
1 Page Link Analysis and Anchor Text for Web Search Lecture 9 Many slides based on lectures by Chen...
52
1 Page Link Analysis and Anchor Text for Web Search Lecture 9 Many slides based on lectures by Chen Li (UCI) an Raymond Mooney (UTexas)
-
Upload
harvey-richardson -
Category
Documents
-
view
213 -
download
0
Transcript of 1 Page Link Analysis and Anchor Text for Web Search Lecture 9 Many slides based on lectures by Chen...

1
Page Link Analysis and Anchor Text for Web SearchLecture 9
Many slides based on lectures by Chen Li (UCI) an Raymond Mooney (UTexas)

2
PageRank
• Intuition:– The importance of each page should be decided
by what other pages “say” about this page– One naïve implementation: count the # of pages
pointing to each page (i.e., # of inlinks)
• Problem:– We can easily fool this technique by generating
many dummy pages that point to our class page

3
Initial PageRank Idea
• Just measuring in-degree (citation count) doesn’t account for the authority of the source of a link.
• Initial page rank equation for page p:
– Nq is the total number of out-links from page q.
– A page, q, “gives” an equal fraction of its authority to all the pages it points to (e.g. p).
– c is a normalizing constant set so that the rank of all pages always sums to 1.
pqq qN
qRcpR
:
)()(

4
Initial PageRank Idea (cont.)
• Can view it as a process of PageRank “flowing” from pages to the pages they cite.
.1
.09
.05
.05
.03
.03
.03
.08
.08
.03

5
Initial Algorithm
• Iterate rank-flowing process until convergence: Let S be the total set of pages.
Initialize pS: R(p) = 1/|S|
Until ranks do not change (much) (convergence)
For each pS:
For each pS: R(p) = cR´(p) (normalize)
pqq qN
qRpR
:
)()(
Sp
pRc )(/1
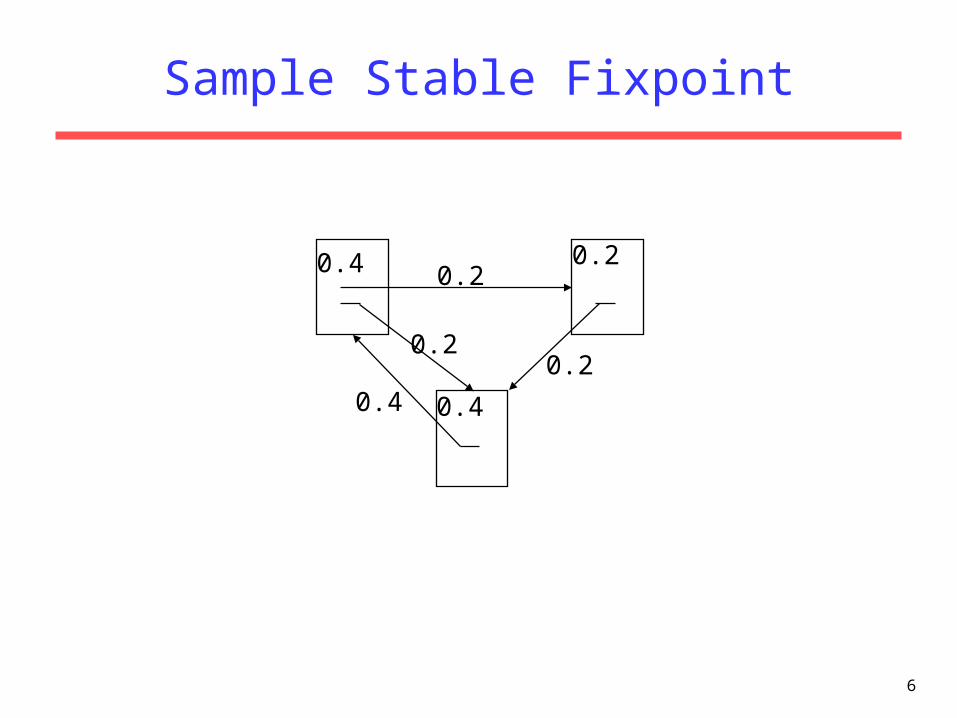
6
Sample Stable Fixpoint
0.4
0.4
0.2
0.2
0.2
0.2
0.4

7
Linear Algebra Version
• Treat R as a vector over web pages.
• Let A be a 2-d matrix over pages where – Avu= 1/Nu if u v else Avu= 0
• Then R=cAR
• R converges to the principal eigenvector of A.
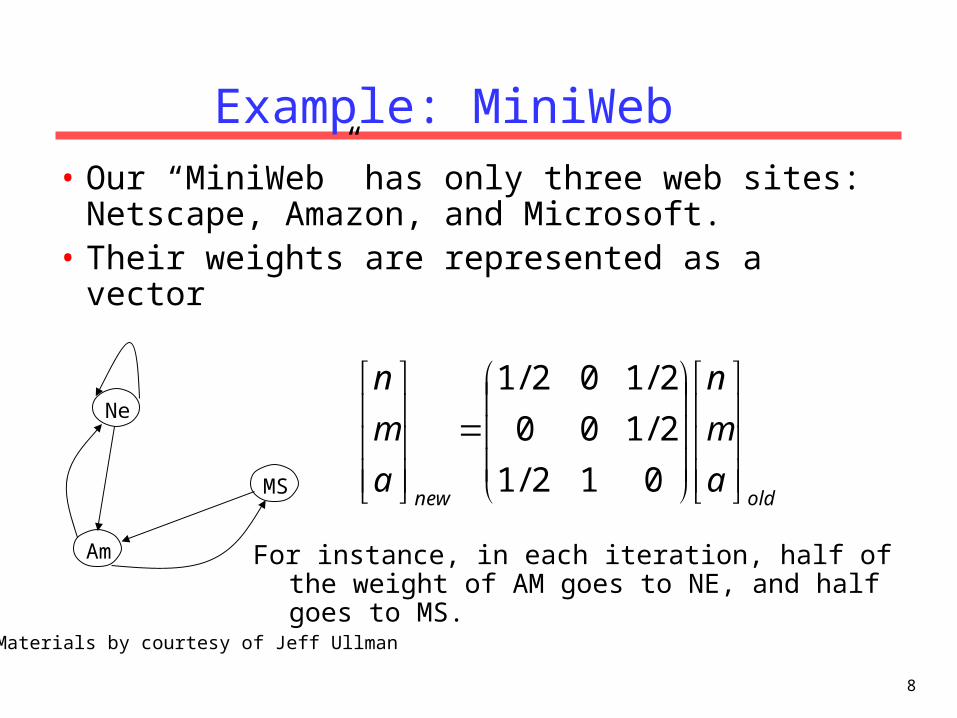
8
Example: MiniWeb
• Our “MiniWeb” has only three web sites: Netscape, Amazon, and Microsoft.
• Their weights are represented as a vector
oldnewa
m
n
a
m
n
012/1
2/100
2/102/1Ne
Am
MS
For instance, in each iteration, half of the weight of AM goes to NE, and half goes to MS.
Materials by courtesy of Jeff Ullman

9
Iterative computation
5/6
5/3
5/6
16/17
16/11
4/5
8/11
2/1
8/9
1
4/3
4/5
2/3
2/1
1
1
1
1
a
m
n
Ne
Am
MSFinal result:
• Netscape and Amazon have the same importance, and twice the importance of Microsoft.
• Does it capture the intuition? Yes.

10
Observations
• We cannot get absolute weights:
– We can only know (and we are only interested in) those relative weights of the pages
• The matrix is stochastic (sum of each column is 1). So the iterations converge, and compute the principal eigenvector of the following matrix equation:
a
m
n
a
m
n
012/1
2/100
2/102/1

11
Problem 1 of algorithm: dead ends!
0
0
0
16/5
16/3
2/1
8/3
4/1
8/5
2/1
4/1
4/3
2/1
2/1
1
1
1
1
a
m
n
Ne
Am
MS
• MS does not point to anybody
• Result: weights of the Web “leak out”
oldnewa
m
n
a
m
n
002/1
2/100
2/102/1

12
Problem 2 of algorithm: spider traps
0
3
0
16/5
16/35
2/1
8/3
2
8/5
2/1
4/7
4/3
2/1
2/3
1
1
1
1
a
m
n
Ne
Am
MS
• MS only points to itself
• Result: all weights go to MS!
oldnewa
m
n
a
m
n
002/1
2/110
2/102/1

13
Google’s solution: “tax each page”
• Like people paying taxes, each page pays some weight into a public pool, which will be distributed to all pages.
• Example: assume 20% tax rate in the “spider trap” example.
2.0
2.0
2.0
002/1
2/110
2/102/1
*8.0
a
m
n
a
m
n
11/5
11/21
11/7
a
m
n

14
The War of Search Engines
• More companies are realizing the importance of search engines
• More competitors in the market: Ask.com, Microsoft, Yahoo!, etc.

15
HITS
• Algorithm developed by Kleinberg in 1998.
• Attempts to computationally determine hubs and authorities on a particular topic through analysis of a relevant subgraph of the web.
• Based on mutually recursive facts:– Hubs point to lots of authorities.– Authorities are pointed to by lots of hubs.

16
Hubs and Authorities
• Motivation: find web pages to a topic– E.g.: “find all web sites about automobiles”
• “Authority”: a page that offers info about a topic– E.g.: DBLP is a page about papers– E.g.: google.com, aj.com, teoma.com, lycos.com
• “Hub”: a page that doesn’t provide much info, but tell us where to find pages about a topic– E.g.: www.searchenginewatch.com is a hub of search
engines– http://www.ics.uci.edu/~ics214a/ points to many biblio-
search engines

17
The hope
AT&T Alice
SprintBob MCI
Long distance telephone companies
HubsAuthorities

18
Base set
• Given text query (say browser), use a text index to get all pages containing browser.– Call this the root set of pages.
• Add in any page that either– points to a page in the root set, or– is pointed to by a page in the root set.
• Call this the base set.
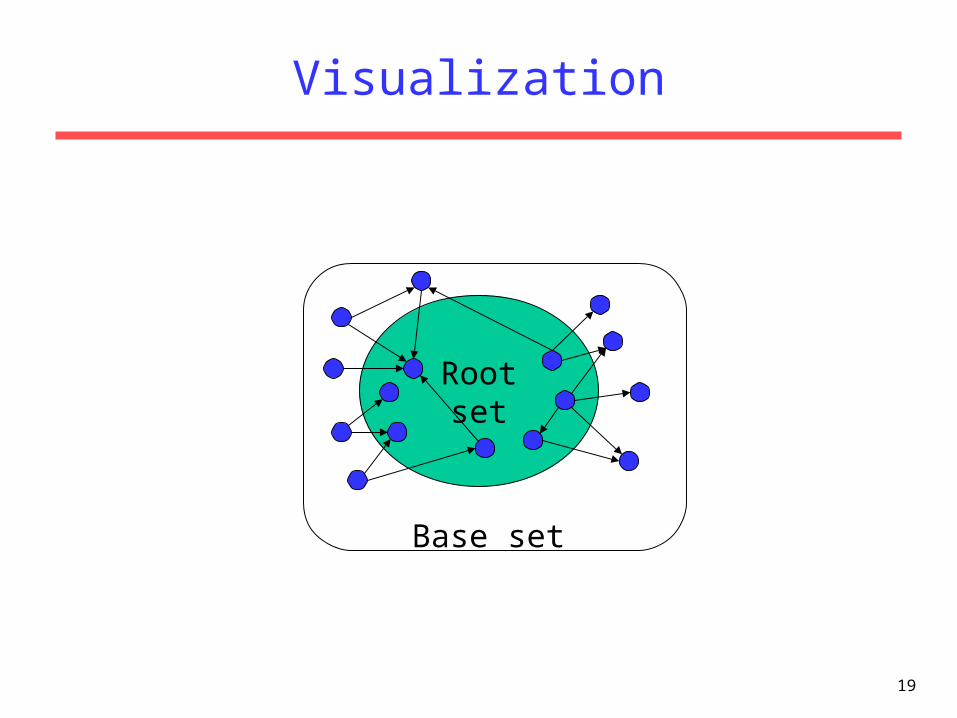
19
Visualization
Rootset
Base set

20
Assembling the base set
• Root set typically 200-1000 nodes.
• Base set may have up to 5000 nodes.
• How do you find the base set nodes?– Follow out-links by parsing root set pages.– Get in-links (and out-links) from a connectivity
server.– (Actually, suffices to text-index strings of the
form href=“URL” to get in-links to URL.)

21
Distilling hubs and authorities
• Compute, for each page x in the base set, a hub score h(x) and an authority score a(x).
• Initialize: for all x, h(x)1; a(x) 1;
• Iteratively update all h(x), a(x);
• After iterations– output pages with highest h() scores as top hubs– highest a() scores as top authorities.
Key

22
Iterative update
• Repeat the following updates, for all x:
yx
yaxh
)()(
xy
yhxa
)()(
x
x

23
Scaling
• To prevent the h() and a() values from getting too big, can scale down after each iteration.
• Scaling factor doesn’t really matter:– we only care about the relative values of the
scores.

24
How many iterations?
• Claim: relative values of scores will converge after a few iterations:– in fact, suitably scaled, h() and a() scores settle
into a steady state!
– proof of this comes later.
• We only require the relative orders of the h() and a() scores - not their absolute values.
• In practice, ~5 iterations get you close to stability.

25
Iterative Algorithm
• Use an iterative algorithm to slowly converge on a mutually reinforcing set of hubs and authorities.
• Maintain for each page p S:– Authority score: ap (vector a)
– Hub score: hp (vector h)
• Initialize all ap = hp = 1
• Maintain normalized scores:
12 Sp
ph 12 Sp
pa

26
HITS Update Rules
• Authorities are pointed to by lots of good hubs:
• Hubs point to lots of good authorities:
pqq
qp ha:
qpq
qp ah:

27
Illustrated Update Rules
2
3
a4 = h1 + h2 + h3
1
5
7
6
4
4h4 = a5 + a6 + a7

28
HITS Iterative Algorithm
Initialize for all p S: ap = hp = 1
For i = 1 to k:
For all p S: (update auth. scores)
For all p S: (update hub scores)
For all p S: ap= ap/c c:
For all p S: hp= hp/c c:
pqq
qp ha:
qpq
qp ah: 1/ 2
Spp ca
1/ 2 Sp
p ch
(normalize a)
(normalize h)

29
Example: MiniWeb
Ne
Am
MS
011
100
111
M
oldnew AMH **
a
m
n
h
h
h
H
a
m
n
a
a
a
A
oldT
new HMA **
oldT
new HMMH ***
Normalization!
Therefore:
oldT
new AMMA ***

30
Example: MiniWeb
Ne
Am
MS
011
100
111
M
011
101
101TM
202
011
213TMM
211
122
122
MM T
2
31
31
84
114
114
18
24
24
4
5
5
1
1
1
A
31
1
32
96
36
132
20
8
28
4
2
6
1
1
1
H

31
Convergence
• Algorithm converges to a fix-point if iterated indefinitely.
• Define A to be the adjacency matrix for the subgraph defined by S.– Aij = 1 for i S, j S iff ij
• Authority vector, a, converges to the principal eigenvector of ATA
• Hub vector, h, converges to the principal eigenvector of AAT
• In practice, 20 iterations produces fairly stable results.

32
Results
• Authorities for query: “Java”– java.sun.com– comp.lang.java FAQ
• Authorities for query “search engine”– Yahoo.com– Excite.com– Lycos.com– Altavista.com
• Authorities for query “Gates”– Microsoft.com– roadahead.com

33
Result Comments
• In most cases, the final authorities were not in the initial root set generated using Altavista.
• Authorities were brought in from linked and reverse-linked pages and then HITS computed their high authority score.

34
Comparison
PagerankPros
– Hard to spam– Computes quality signal for all pages
Cons– Non-trivial to compute– Not query specific– Doesn’t work on small graphs
Proven to be effective for general purpose ranking
HITS & VariantsPros
– Easy to compute, real-time execution is hard [Bhar98b, Stat00]
– Query specific– Works on small graphs
Cons– Local graph structure can be
manufactured (spam!)– Provides a signal only when there’s
direct connectivity (e.g., home pages)
Well suited for supervised directory construction

35
Tag/position heuristics
• Increase weights of terms – in titles
– in tags
– near the beginning of the doc, its chapters and sections

36
Anchor text (first used WWW Worm - McBryan [Mcbr94])
Here is a great picture of a tiger
Tiger image
Cool tiger webpage
The text in the vicinity of a hyperlink isdescriptive of the page it points to.

37
Two uses of anchor text
• When indexing a page, also index the anchor text of links pointing to it.– Retrieve a page when query matches its anchor
text.
• To weight links in the hubs/authorities algorithm.
• Anchor text usually taken to be a window of 6-8 words around a link anchor.
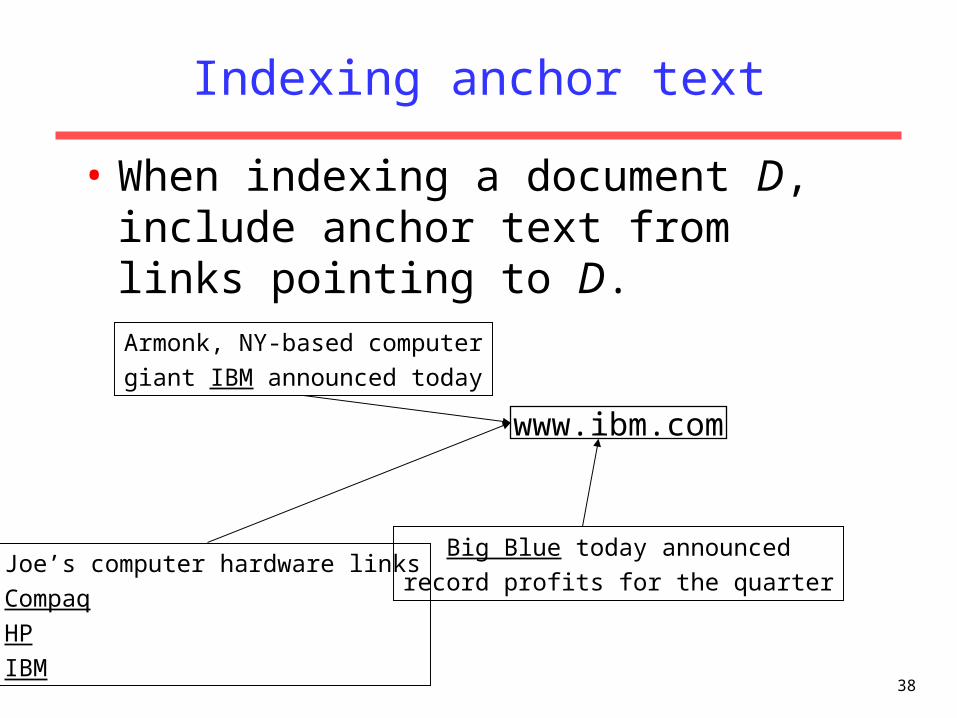
38
Indexing anchor text
• When indexing a document D, include anchor text from links pointing to D.
www.ibm.com
Armonk, NY-based computergiant IBM announced today
Joe’s computer hardware linksCompaqHPIBM
Big Blue today announcedrecord profits for the quarter

39
Indexing anchor text
• Can sometimes have unexpected side effects - e.g., evil empire.
• Can index anchor text with less weight.

40
Weighting links
• In hub/authority link analysis, can match anchor text to query, then weight link.
yx
yaxh
)()(
xy
yhxa
)()( )(),()(
)(),()(
yhyxwxa
yayxwxh
xy
yx

41
Weighting links
• What is w(x,y)?
• Should increase with the number of query terms in anchor text.– E.g.: 1+ number of query terms.
www.ibm.comArmonk, NY-based computergiant IBM announced todayx y
Weight of this link for query computer is
2.

42
Weighted hub/authority computation
• Recall basic algorithm:– Iteratively update all h(x), a(x);
– After iteration, output pages with• highest h() scores as top hubs• highest a() scores as top authorities.
• Now use weights in iteration.
• Raises scores of pages with “heavy” links.
Do we still have convergence of scores?
To what?

43
Anchor Text
• Other applications– Weighting/filtering links in the graph
• HITS [Chak98], Hilltop [Bhar01]
– Generating page descriptions from anchor text [Amit98, Amit00]

Behavior-based ranking

Behavior-based ranking
• For each query Q, keep track of which docs in the results are clicked on
• On subsequent requests for Q, re-order docs in results based on click-throughs
• First due to DirectHit AskJeeves
• Relevance assessment based on– Behavior/usage– vs. content

Query-doc popularity matrix B
Queries
Docs
q
j
Bqj = number of times doc j
clicked-through on query q
When query q issued again, order docsby Bqj values.

Issues to consider
• Weighing/combining text- and click-based scores.
• What identifies a query?– Ferrari Mondial– Ferrari Mondial– Ferrari mondial– ferrari mondial– “Ferrari Mondial”
• Can use heuristics, but search parsing slowed.

Vector space implementation
• Maintain a term-doc popularity matrix C– as opposed to query-doc popularity– initialized to all zeros
• Each column represents a doc j– If doc j clicked on for query q, update Cj Cj +
q (here q is viewed as a vector).
• On a query q’, compute its cosine proximity to Cj for all j.
• Combine this with the regular text score.

Issues
• Normalization of Cj after updating
• Assumption of query compositionality– “white house” document popularity derived
from “white” and “house”
• Updating - live or batch?

Basic Assumption
• Relevance can be directly measured by number of click throughs
• Valid?

Validity of Basic Assumption
• Click through to docs that turn out to be non-relevant: what does a click mean?
• Self-perpetuating ranking
• Spam
• All votes count the same

Variants
• Time spent viewing page– Difficult session management– Inconclusive modeling so far
• Does user back out of page?
• Does user stop searching?
• Does user transact?


















