
1 Mobile File Systems: Disconnected and Weakly Connected File Systems 3/29/2004 Richard Yang.
34
1 Mobile File Systems: Disconnected and Weakly Connected File Systems 3/29/2004 Richard Yang
-
Upload
linda-bennett -
Category
Documents
-
view
224 -
download
0
Transcript of 1 Mobile File Systems: Disconnected and Weakly Connected File Systems 3/29/2004 Richard Yang.

1
Mobile File Systems:
Disconnected and Weakly
Connected File Systems
3/29/2004
Richard Yang

2
Outline
Admin. and recap Mobile file systems

3
Admin.
Project proposal due tonight at 11:59pm
at most one page• what is the problem?• why is the problem important?• what are the major potential challenges?• what is your methodology?
please send proposal to the TA• [email protected]

4
Recap
TCP: congestion control in Internet TCP is window-based
• to use the stability of self-clocking TCP adjusts congestion window using the AIMD
algorithm • AIMD is a special case of the simplest possible control
rules• AIMD constantly probes for network state
– achieves dynamic equilibrium– converges to fair state
Throughput of TCP is inverse proportional to the square root of packet loss rate in wireless networks, losses due to corruption are
interpreted as congestion indication, and thus slow down transmission
indirect TCP splits connection snoop TCP preserves end-to-end semantics

5
Outline
Admin. and recap Mobile file systems
6
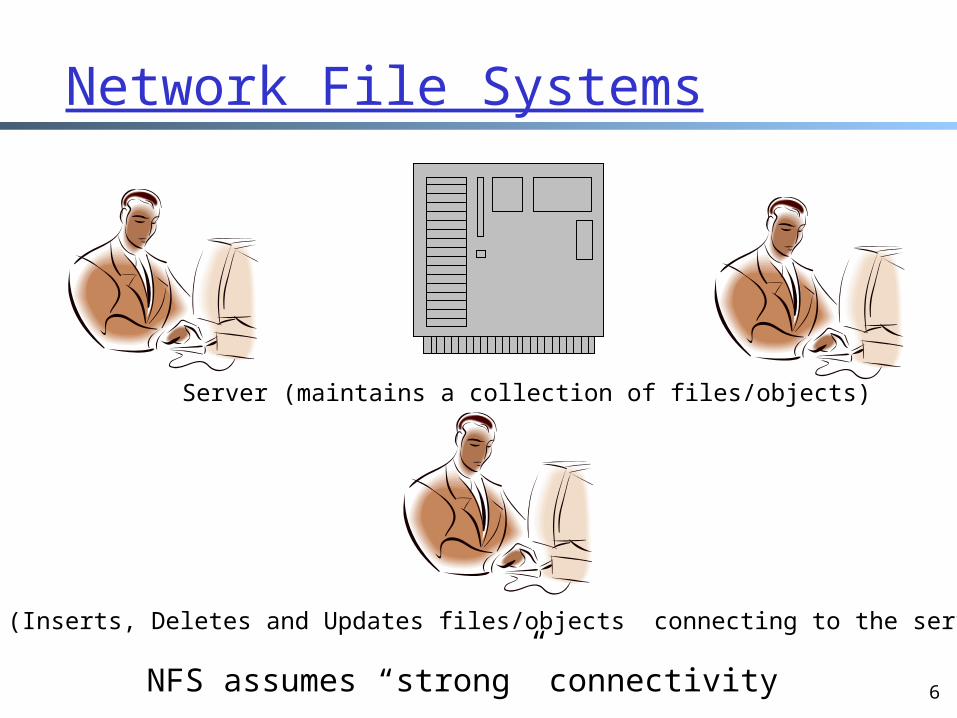
Server (maintains a collection of files/objects)
Client (Inserts, Deletes and Updates files/objects connecting to the server)
Network File Systems
NFS assumes “strong” connectivity
7
Motivation
Mobile users must be able to work on files (on remote file servers) while disconnected/weakly connected, e.g. take your laptop on a trip

8
The Problems Caused by Disconnection
Read miss stalls progress (the user has to stop working)
Delayed write may cause inconsistency if concurrent writes
by multiple users are allowed
9
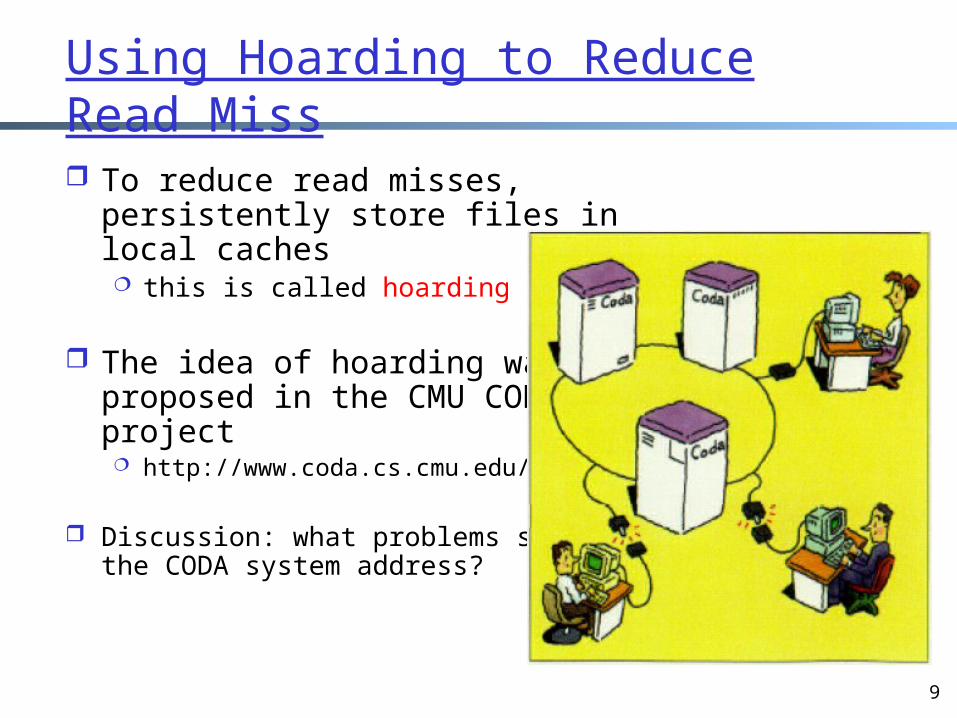
To reduce read misses, persistently store files in local caches this is called hoarding
The idea of hoarding was proposed in the CMU CODA project http://www.coda.cs.cmu.edu/
Discussion: what problems should the CODA system address?
Using Hoarding to Reduce Read Miss

10
Volume is the unit for management (hoarding), e.g., the home directory of one user a volume is smaller than a disk partition typical volume size is 10MB
Each volume is a partial sub tree of the name space%cfs makemount u.smith /coda/usr/smith
CODA Groups Files into Volumes

11
HOARDING
EmulationReintegration
Disconnection
Physical Reconnection
Logical Reconnection
Hoard data in anticipationof disconnectionPrioritized cache management
Log replayResolving conflicts
(write/write)Seek user feedback in doubt
Persistent storageClient Modification Log
(CML)
CODA Client (Venus)
12
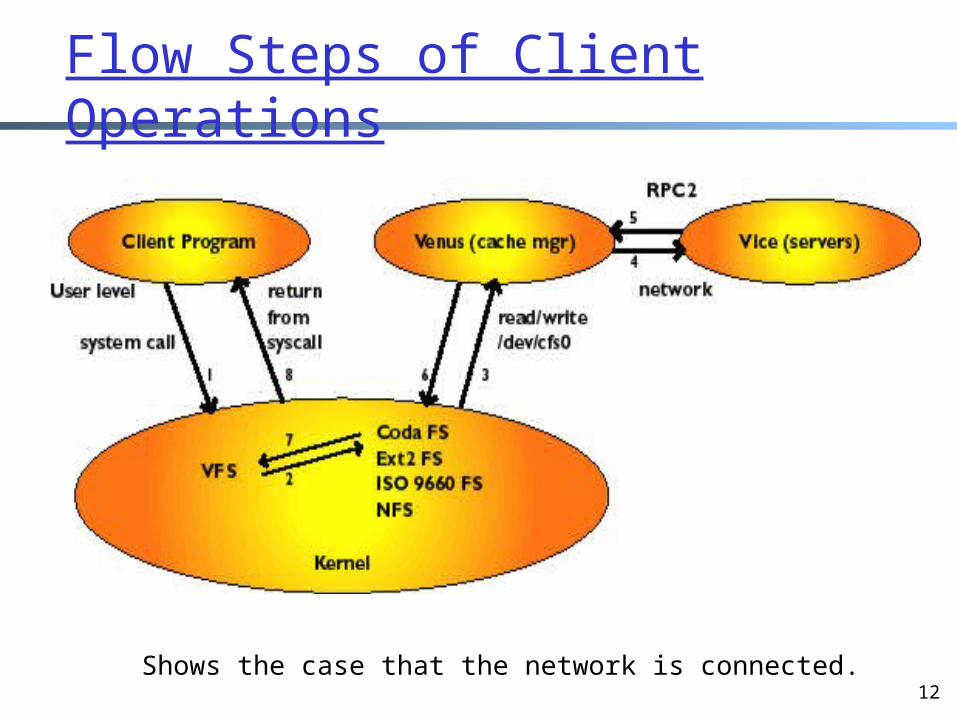
Flow Steps of Client Operations
Shows the case that the network is connected.

13
File Servers and Replicated Servers CODA uses replicated
file servers to improve reliability
A volume is stored by a group of servers called its Volume Storage Group (VSG)
Read/write read-one write-many
AVSG: All accessible VSG members
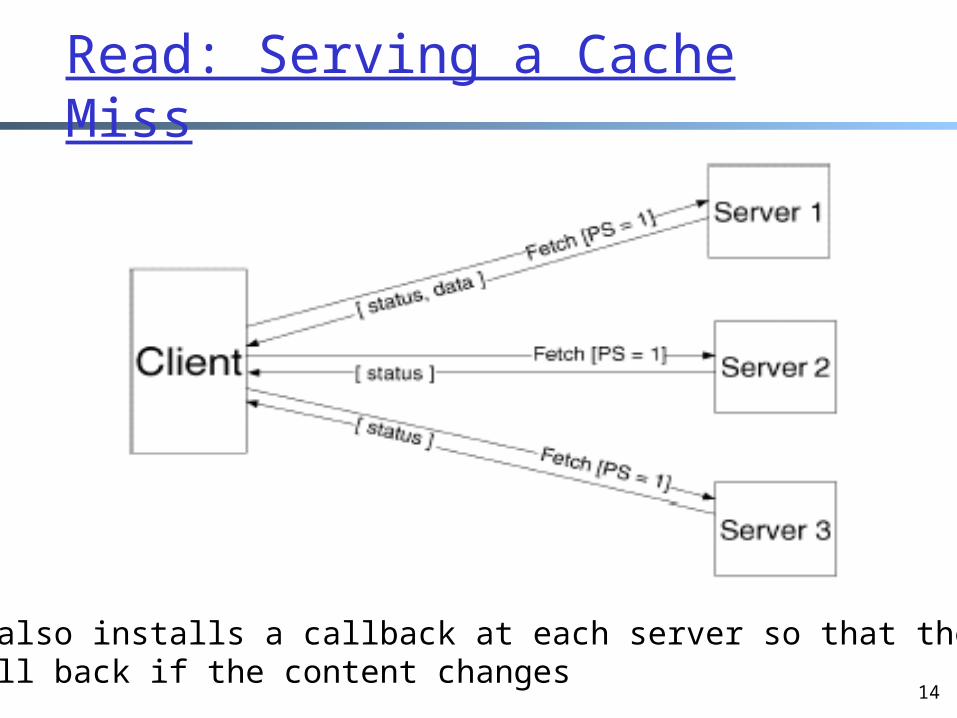
14
Read: Serving a Cache Miss
A read also installs a callback at each server so that the serverwill call back if the content changes
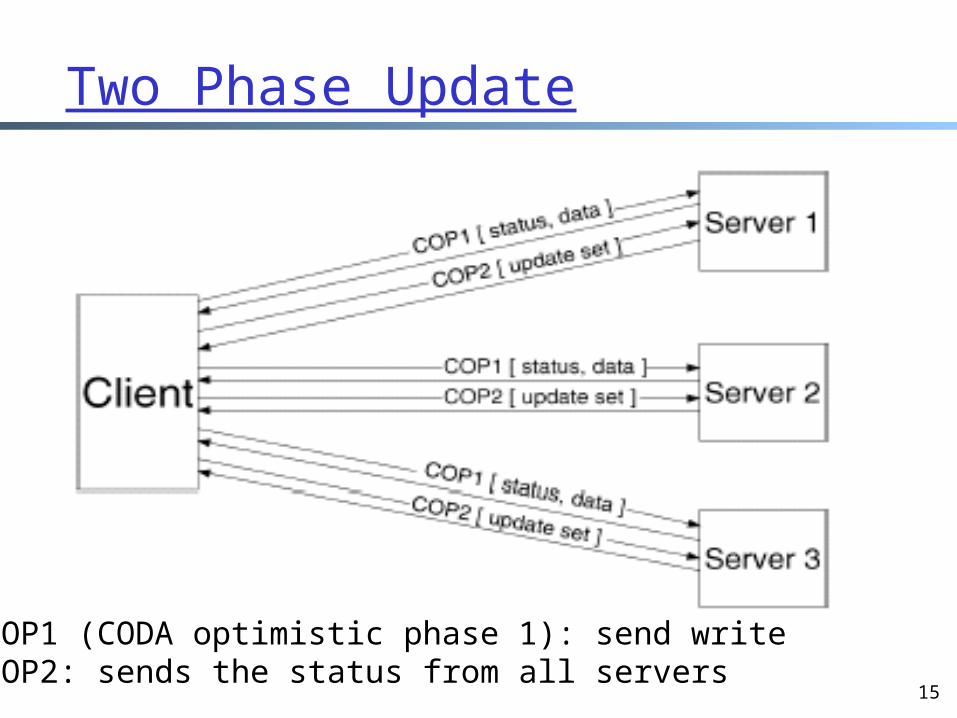
15
Two Phase Update
COP1 (CODA optimistic phase 1): send writeCOP2: sends the status from all servers

16
Summary: CODA

17
Outline
Admin. and recap Mobile file systems: dealing with
disconnection CODA SEER: automatic prediction of related files to
avoid user manual configuration of hoarding

18
SEER: A Predictive Hoarding System
Views user activities as composed of projects than individual files
Predicates files in a project and fetch them together
Discussion: how do you predicate all of the files a project may use?

19
Basic Idea of SEER: Semantic Distance Quantifies user’s intuition about
relationship between files smaller closer in relation
Infers relationship static (done by an external investigator), e.g.,
• observes directory structure/membership• observes naming convention• #include in a program
dynamic• watches user’s behavior

20
Lifetime Semantic Distance Looks at file open/close (not file content !!) Lifetime semantic distance:
The lifetime semantic distance between an open of file A and an open of file B is defined as 0 if A has not been closed before B is opened and the number of intervening file opens (including the open of B) otherwise
End up with multiple lifetime semantic distances between two events of two files needs distance between two files, not events uses geometric mean to convert to a single distance
AB C
D
Time
Sample file access sequence
Semantic distance- AB , AC is 0- AD is 3

21
Basic Idea of SEER: Clustering Algorithm Based on algorithm by
Jarvis and Patrick Allows overlapping clusters Steps
calculates n nearest neighbors for each file
Phase 1: if two points (files here) have at least kn overlapping neighbors, combine their clusters into one
Phase 2: if two points have more than kf but less than kn overlapping neighbors, overlap the clusters i.e. add each to the other cluster
Relation Action
kn ≤x
kf≤x<kn
x<kf
Combine clustersOverlapping clustersNo action
Summary of clustering algorithm

22
Example
Seven files , A-G{A} {B} {C} {D} {E} {F}
{G}
Phase 1: {A, B} {A, B, C}{D, E} {F, G} {D,E,F, G}
Phase 2:two pairs {A, C} {C, D}
{A, C} : same cluster already{C, D} overlap clusters
Final result {A, B, C, D} {C,D, E, F,G}
Number of shared neighbors
From ToA B C D E F G
ABCDEFG
kn kf kn kf kn
kn kn

23
Using Both Lifetime Semantic Distance and the Input of External Investigator
Essentially gives application specific info
Example large directory distance => looser
relationship• subtract directory distance from shared neighbor
count

24
Real World Anomalies: Special Cases Many special cases
authors use a heuristic to solve each
Shared libraries e.g. : library X might cause unwanted clustering Heuristic: files which represent more than a
certain percentage of all references marked as “frequently-referenced” (1%)
• eliminate from calculation

25
Critical files (e.g. : startup files) rarely accessed but important use heuristic and hoard
• special control file that specifies such files• detect by names e.g. .login etc
Temporary files (e.g. : in /tmp) transient and don’t depict correct relationship might displace other important files from n closest heuristic: ignore files in /tmp etc. completely
Simultaneous access e.g. : read mail & compile code independent streams are intermixed ! maintain reference-history on a per-process basis
More Special Cases …

26
Performance Evaluation: Methodology
Inputtrace-driven simulation
MeasureMiss-free hoard size
• size a hoard would have to be to ensure no misses (remember our goal!)

27
Results
Graph : sorted working set sizes Seer consistently slightly more than working set size
MB

28
Outline
Admin. and recap Mobile file systems: dealing with
disconnection CODA: hoarding SEER: automatic prediction of related files to
avoid user manual configuration of hoarding Bayou: automatic conflict update

29
Bayou: Managing Update Conflicts
Basic idea: application specific conflict detection and update
Two mechanisms for automatic conflict detection and resolution dependency check merge procedure

30
Bayou Write Operation: An Example

31
Outline
Admin. and recap Mobile file systems: dealing with
disconnection CODA: hoarding SEER: automatic prediction of related files to
avoid user manual configuration of hoarding Bayou: automatic conflict update
Mobile file systems: dealing with low bandwidth LBFS: efficient file comparison and merging
32
Motivation
The CODA system assumes that modifications are kept as logs (CML) a user sends the logs to the servers to update
If the storage of a client is limited, it may not be able to save logs then upon reconnection, the cache manager needs to
find the difference between the stored file and its local cached copy
same problem exists for the rsync tool !
Question: how to efficiently compare the differences of two remote files (when the network connection is slow)?

33
LBFS: Low-Bandwidth File System
Break Files into chunks and transfer only modified chunks
Fixed chunk size does not work well why?

34
Flexible Chunk Size
Compute hash value of every 48 byte block if the hash value equals to a magic value, it is
a chunk boundary










![Synchronization of weakly coupled canard oscillators · by the theory of weakly coupled oscillators (which is valid for moderate coupling strengths in various systems [14, 56]) but](https://static.fdocuments.us/doc/165x107/5e6b43af7f31a13cd8257da0/synchronization-of-weakly-coupled-canard-oscillators-by-the-theory-of-weakly-coupled.jpg)






![Chemical Engineering Journal - Microfluidicsmicrofluidics.stanford.edu/Publications/Capacitive deionization/Palko2018... · weakly soluble oily species [15]. Reverse osmosis systems](https://static.fdocuments.us/doc/165x107/5e2ae76033977d4114735080/chemical-engineering-journal-microf-deionizationpalko2018-weakly-soluble.jpg)
