
1 Documentary linguistics Compilation and exploitation of...
12
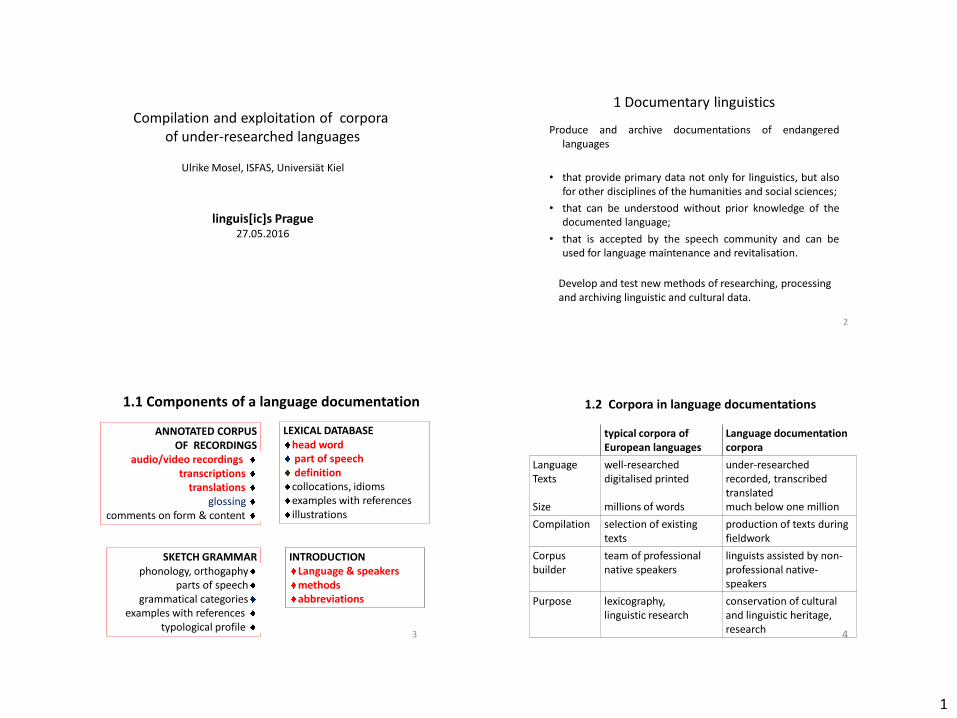
1 Compilation and exploitation of corpora of under-researched languages Ulrike Mosel, ISFAS, Universiät Kiel linguis[ic]s Prague 27.05.2016 2 1 Documentary linguistics Produce and archive documentations of endangered languages • that provide primary data not only for linguistics, but also for other disciplines of the humanities and social sciences; • that can be understood without prior knowledge of the documented language; • that is accepted by the speech community and can be used for language maintenance and revitalisation. Develop and test new methods of researching, processing and archiving linguistic and cultural data. SKETCH GRAMMAR phonology, orthogaphy parts of speech grammatical categories examples with references typological profile INTRODUCTION Language & speakers methods abbreviations LEXICAL DATABASE head word part of speech definition collocations, idioms examples with references illustrations ANNOTATED CORPUS OF RECORDINGS audio/video recordings transcriptions translations glossing comments on form & content 1.1 Components of a language documentation 3 typical corpora of European languages Language documentation corpora Language Texts Size well-researched digitalised printed millions of words under-researched recorded, transcribed translated much below one million Compilation selection of existing texts production of texts during fieldwork Corpus builder team of professional native speakers linguists assisted by non- professional native- speakers Purpose lexicography, linguistic research conservation of cultural and linguistic heritage, research 4 1.2 Corpora in language documentations
Transcript of 1 Documentary linguistics Compilation and exploitation of...
1
Compilation and exploitation of corpora of under-researched languages
Ulrike Mosel, ISFAS, Universiät Kiel
linguis[ic]s Prague 27.05.2016
2
1 Documentary linguistics
Produce and archive documentations of endangered languages
• that provide primary data not only for linguistics, but also for other disciplines of the humanities and social sciences;
• that can be understood without prior knowledge of the documented language;
• that is accepted by the speech community and can be used for language maintenance and revitalisation.
Develop and test new methods of researching, processing and archiving linguistic and cultural data.
SKETCH GRAMMAR phonology, orthogaphy
parts of speech grammatical categories
examples with references typological profile
INTRODUCTION Language & speakers methods abbreviations
LEXICAL DATABASE head word part of speech definition collocations, idioms examples with references illustrations
ANNOTATED CORPUS OF RECORDINGS
audio/video recordings transcriptions
translations glossing
comments on form & content
1.1 Components of a language documentation
3
typical corpora of European languages
Language documentation corpora
Language Texts Size
well-researched digitalised printed millions of words
under-researched recorded, transcribed translated much below one million
Compilation selection of existing texts
production of texts during fieldwork
Corpus builder
team of professional native speakers
linguists assisted by non-professional native-speakers
Purpose lexicography, linguistic research
conservation of cultural and linguistic heritage, research 4
1.2 Corpora in language documentations

2
5
linguists speech community
kind of
language
spontaneous language;
variety of genres and registers
”good” language;
content “as many an as varied records as
practically feasible”
(Himmelmann 2006)
important genres;
educational materials
format/
media
electronic corpus audio and video
recordings with transcription and
translation, rich annotation,
printed materials
orthography based on linguistic principles
(phonological)
orthography similar to that
of a/the dominant language
lexicon electronic lexical database (encyclopedic) dictionary
on paper
1.3 The linguists' and the speech community's corpus
Bougainville, Papua New Guinea
6
1.4 The Teop language corpus
Austronesian, Oceanic, 6000 speakers Research on Teop since 1994
text “any artefact containing language usage
(book ..., t-shirt slogan, .... speech, conversation)”
(McEnery & Hardie 2012:250)
corpus “collection of sampled texts, written or spoken,
in machine readable form
which may be annotated with various forms
of linguistic information” (McEnery et al. 2006:4)
2.1 Basic concepts of corpus linguistics
7
2 What are corpora? 2.2 Corpus typology
1. Monitor corpus / dynamic corpus “grows in size over time ... contains a variety of materials”
(McEnery & Hardie 2012:6)
2. Sample text corpus designed in order to be representative of a particular language variety within a specified sampling
frame (McEnery & Hardie 2012:8, 250)
8
3. Opportunistic corpora “represent nothing more or less than the data that it was possible to gather for a specific task.” (McEnery & Hardie 2012:11)
4. Parallel corpora “Parallel corpora consist of a souce text and its translation into one or more languages.” (Aimer, Karin. 2008:276)

3
5. Contrastive corpora Two corpora or subcorpora that represent two registers, genres or other varieties of the same language. (Tognini Bonelli 2010:21-22)
6. Artificial corpora • “They are constructed with whatever data may be accessible
at the lowest cost, and essentially regardless of the documents’ content ...
• the material has no social or cultural rationale for being collected ...
• ad-hoc respositories of language materials.” (Ostler 2008)
for example Recordings of stimulus-based elicitation
7. Multimedia corpora have transcripts that are aligned with audio or video recordings. (Lee 2010:114)
8. Multimodal corpora are multimedia corpora that contain “digitised collection of language and communication-related material, drawing on more than one modality ... accompanied by transcriptions and annotations or codings based on the material.“ (Allwood:2008:208)
Modalities: speech, eye & head movements, body postures, gestures, facial expressions ... (Wittenburg 2008:664)
2.3 Classification of LD corpora
Monitor corpus as long as the corpus is growing
Sample text corpus -
Opportunistic corpus all, because the collection of texts is done during field reaserch
Parallel unidirectional, e.g. Teop texts with English translation
Contrastive texts about the same topics, but produced in diffferent registers or genres
Artificial Elicitations - “no social or cultural rationale“
Multimedia audio/video recordings with transcriptions
Multimodal audio/video recordings with transcriptions (and codings for non-verbal comunication)
2.4 Genres and registers (Biber & Conrad 2009. Register, genre, and style. CUP, Ch. 1 & 2)
Linguistic variation is systematic Selection of linguistic features depends on non-linguistic factors.
12
Different types of texts show different text structures and different features of linguistic form, i.e. phonological, lexical and grammatical features.
Two kinds of classifying texts types: Genres: by structural features: Registers by the pervasive use of certain phonological lexical and grammatical features in particular speech situations.

4
13
Genre Type of text that is used in particular social contexts and has a particular structure which is indicated by certain formal features such as speech formulas at the beginning or end of the text.
Dear Sir, .... With kind regards, Yours sincerely John Smith
2.4.1 Genre
Once upon a time ... ... lived happily ever after
2.4.2 Register analysis
3.Interprete the relationship between situational characteristics and pervasive linguistic features.
2. Identify typical (pervasive) linguistic features.
1. Identify the situational characteristics of the texts.
Register Type of text that occurs in certain speech situations and shows certain phonological, grammatical and lexical features throughout any text of this type with a significantly higher frequency as in other text types.
Biber, Douglas 2006. University language.
Biber 2006: 48: Content word classes across registers
Situational characteristics of text varieties (abbrev. from Biber & Conrad 2009:40)
Participants and their social characteristics
Mode (speech /writing), Medium (taped, radio, handwritten ...)
Production circumstances (real time, planned, edited, ...)
Setting (private / public; ...)
Communicative purposes (narrate, report, describe, ...)
Topic
The situational chatacteristics should be documented in the metadata of each text.
16

5
3.1 Awetí
3. Content and structure of corpora of under-researched languages
3.2 Beaver Archive Athabaskan, Canada DoBeS – Project
3.3 Saliba / Logea - Oceanic , Papua New Guinea 4 Structure and content of the Teop Language Corpus
(on my computer)
4 Genres: 1. legends 2. personal narratives 3. descriptions 4. unconnected example sentences
3 Modes 1. sponateously spoken (R) 2. edited transcriptions (E) 3. written texts (W)
contrastive subcorpora: 01-02, 04-05, 07-08

6
4.1 Different modes: spontaneous speech vs. planned writing
1. original recordings with transcriptions
2. edited versions of the transcription with recording readings
The contrastive subcorpora
1. show alternative ways of expressing the same content
2. provide a new type of data for research on
what speakers actually do
when they put an oral text into writing
21 (Mosel 2015)
Changes in edited legends
Elaboration: addition of linguistic units words, phrases, clauses
Linkage: paratactic constructions > > complex sentences Compression: more information in a single linguistic unit Decompression: complex sentences > paratactic constructions (Mosel 2015)
22
4.2 Narratives vs procedural texts
Narratives Procedural texts
Paratactic clauses Coordinate clauses
Adverbial clause constructions: ‘when ..., then...’
Sequence of past events Regular fixed order of actions
> create a corpus of contrastive narrative and procedural texts minimise variables
23
Choose the very same topic!
Create contrastive narrative and procedural texts about butchering a chicken

7
procedural text: 40 clauses, 12 adverbial clause constr. narrative text: 53 clauses, no adverbial clauses 13 paratactic clauses
Make series of photographs and use them as stimuli for 1. the description of how to butcher a chicken 2. the narrative of how the twins helped
their father butchering a chicken told by their mother
25
5 Types of data
_____ corpus content _______ corpus exploitation
5.1 Types of data in the Teop Language Corpus
Spoken language Written languge
raw data audio recordings
manuscripts by native speakers
primary data by native speakers
transcriptions by native speakers
edited versions of manuscripts
edited versions of transcriptions
primary data by linguists
transcriptions by a phonetician
translations translations
structural data morphological segmentation and glossing
28
5.2 Types of data in ELAN files
Minimal annotation in ELAN
wav file utterance ID transcription translation

8
utterance ID phonetic transcription orthography free translation morph. segmentation glosses
Phonetic and morphlogical annotation
The phonetic transcrption done by a phonetician took several weeks.
legend duration ca. 5 minutes
30
Syntactic annotation 1) grammatical units (Erfurt Referentiality Project) 2) glossing 3) GRAID (Grammatical Relations and Animacy In Discourse, Haig & Schnell)
1. respect self-correction 2. mark clause boundaries by # 3. insert ZERO for zero anaphora, gloss it 4. annotate argument relations (S/A/P) in GRAID
b) “Hospitality of constructions“
certain positions in constructions accommodate a greater variety of grammatical and semantic lexeme classes than others some even neutralise word class distinctions (Hopper & Thompson 1984)
Which forms are accommodated in position X?
a) Distribution of particular word forms and phrases
In which positions is form X used?
31
6 Corpus analysis 6.1 Negated VCs – single layer search
discontinuous negative morpheme: saka/sa ______ haa task: search for all words that enter the empty slot between saka or sa and the second component haa which may have clitics haa=na, haa=ra, haa=ri
regular expression: (\bsa(ka)?\b .* \bhaa
Which words occur in negated VCs?
32

9
33
\bsa(ka)?\b .* \bhaa
Search for the negative contruction frame
910 annotations
34
listen bird person good finished person stay
\bsa(ka)?\b .* \bhaa
NEG HEAD (ADV) NEG (=IPFV)
1. Identify the elements constituting the constructional frames1 of NPs (referential phrases) VCes (TAM marked predicates):
6.2 Noun/verb distinction (a complex single layer search)
A constructional frame consists of functional morphs and empty, syntactically defined head and modifier positions for content words or stems.
Workflow
1) cf. the notions of collocational frame works, grammar patterns and colligates in Stefanowitsch & Gries 2009: 936-937
35
2. Identify the elements that directly precede or follow the empty head position for the content word
noun/verb distinction (cont.)
Workflow (cont.)
3. Construct regular expressions for the head position
4. select a few prototypical frequent action and object words e.g. ‘do, make‘, ‘say‘, ‘person‘, .‘thing‘, and search
NP: ART (QUANT ADJ etc.) HEAD VC: (NEG) TAM (ADV) etc. HEAD
5. Repeat the procedure with modifier positions
36
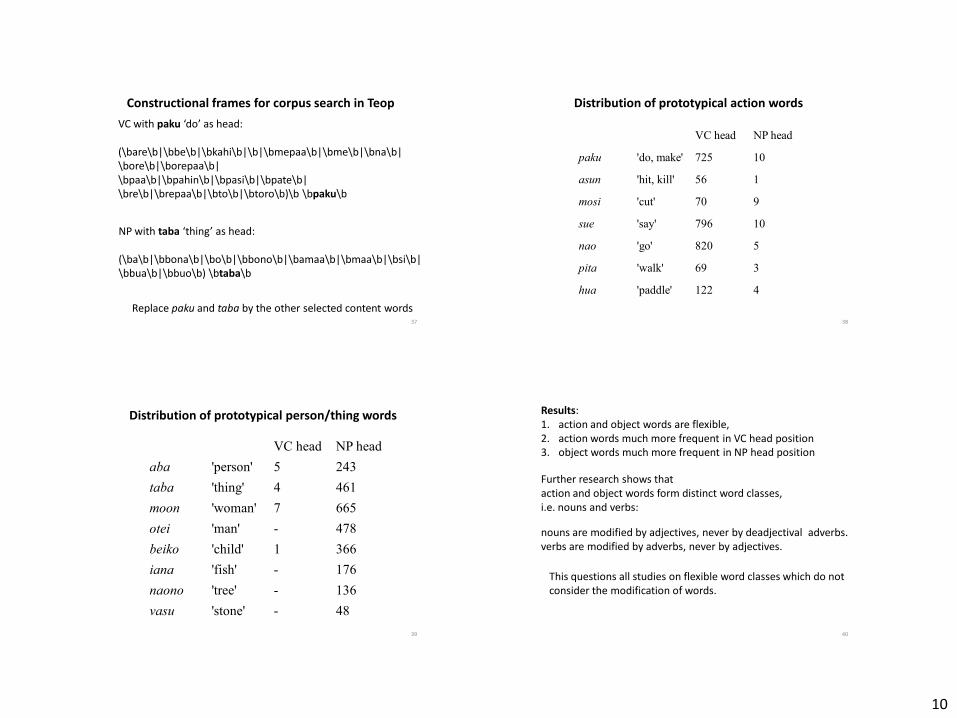
10
VC with paku ‘do’ as head: (\bare\b|\bbe\b|\bkahi\b|\b|\bmepaa\b|\bme\b|\bna\b| \bore\b|\borepaa\b| \bpaa\b|\bpahin\b|\bpasi\b|\bpate\b| \bre\b|\brepaa\b|\bto\b|\btoro\b)\b \bpaku\b
NP with taba ‘thing’ as head: (\ba\b|\bbona\b|\bo\b|\bbono\b|\bamaa\b|\bmaa\b|\bsi\b| \bbua\b|\bbuo\b) \btaba\b
Constructional frames for corpus search in Teop
37
Replace paku and taba by the other selected content words
VC head NP head
paku 'do, make' 725 10
asun 'hit, kill' 56 1
mosi 'cut' 70 9
sue 'say' 796 10
nao 'go' 820 5
pita 'walk' 69 3
hua 'paddle' 122 4
Distribution of prototypical action words
38
VC head NP head
aba 'person' 5 243
taba 'thing' 4 461
moon 'woman' 7 665
otei 'man' - 478
beiko 'child' 1 366
iana 'fish' - 176
naono 'tree' - 136
vasu 'stone' - 48
Distribution of prototypical person/thing words
39
Results: 1. action and object words are flexible, 2. action words much more frequent in VC head position 3. object words much more frequent in NP head position
Further research shows that action and object words form distinct word classes, i.e. nouns and verbs:
This questions all studies on flexible word classes which do not consider the modification of words.
40
nouns are modified by adjectives, never by deadjectival adverbs. verbs are modified by adverbs, never by adjectives.

11
41
6.3. Comparison (a simple mutiple layer search)
How is comparison expressed in Teop?
'X is bigger/smaller than Y'
Search for than on the translation tier. Search for .* on the transcription tier
There is not morphological comparative in Teop.
Search for the Teop adjectives ‘big‘ and and ‘small‘ and examine more than 1000 tokens?
42
Simple multiple layer search for “comparatives“
43
Simple multiple layer search for comparatives
transcription tier: “wild card“ translation tier: “than“
The exceed comparative construction
(The drummer is big exceeding the tang.)
44
(The babarii is the small of the adult barii.)
The inalieanble possessive comparative construction
Comparative constructions
A babarii a rutaa n= a barii .... the young drummer the small 3SG.POSS= the drummer

12
45
The alieanble possessive comparative construction
Comparative constructions
Eve a beera te =a kavara ri= o goroto vai it the big of =the whole 3PL.POSS=the.PL turtle this ‘It is the big of the whole of the turtles‘
Possessive comparative constructions are not mentioned in Stassen 1985, 2013 (WALS)
7 Corpus compilation and grammatical analysis
46
Focus on a few registers/genres. The more diversified the corpus is, the smaller are the subcorpora, and the smaller the probability that you can adequately identify regular patterns of language usuage.
Recommendations for corpus compilation: Use ELAN or a similar tool with an implemented powerful query language. Extended annotation is very time consuming. Document your annotation rules and your search methods. Make your corpus and the metadata accessible. Aim at scientific research that is replicable and falsifiable.


















