
1 CSC 8520 Spring 2013. Paula Matuszek CS 8520: Artificial Intelligence Machine Learning 1 Paula...
64
1 CSC 8520 Spring 2013. Paula Matuszek CS 8520: Artificial Intelligence Machine Learning 1 Paula Matuszek Spring, 2013
-
Upload
edwin-fitzgerald -
Category
Documents
-
view
221 -
download
3
Transcript of 1 CSC 8520 Spring 2013. Paula Matuszek CS 8520: Artificial Intelligence Machine Learning 1 Paula...

1CSC 8520 Spring 2013. Paula Matuszek
CS 8520: Artificial Intelligence
Machine Learning 1
Paula Matuszek
Spring, 2013

2CSC 8520 Spring 2013. Paula MatuszekCSC 8520 Spring 2010. Paula Matuszek
http://xkcd.com/720/

3CSC 8520 Spring 2013. Paula Matuszek
What is learning?• “Learning denotes changes in a system
that ... enable a system to do the same task more efficiently the next time.” –Herbert Simon
• “Learning is constructing or modifying representations of what is being experienced.” –Ryszard Michalski
• “Learning is making useful changes in our minds.” –Marvin Minsky

4CSC 8520 Spring 2013. Paula Matuszek
Why learn?• Understand and improve efficiency of human learning
– Improve methods for teaching and tutoring people (better CAI)
• Discover new things or structure that were previously unknown to humans– Examples: data mining, scientific discovery
• Fill in skeletal or incomplete specifications about a domain– Large, complex AI systems cannot be completely derived by hand
and require dynamic updating to incorporate new information.
– Learning new characteristics expands the domain or expertise and lessens the “brittleness” of the system
• Build software agents that can adapt to their users or to other software agents
• Reproduce an important aspect of intelligent behavior

5CSC 8520 Spring 2013. Paula Matuszek
Learning Systems• Many machine learning systems can be viewed as an
iterative process of – produce a result,
– evaluate it against the expected results
– tweak the system
• Machine learning is also used for systems which discover patterns without prior expected results.
• May be open or black box– Open: changes are clearly visible in KB and understandable
to humans
– Black Box: changes are to a system whose internals are not readily visible or understandable.

6CSC 8520 Spring 2013. Paula Matuszek
Learner Architecture• Any learning system needs to somehow implement
four components:– Knowledge base: what is being learned. Representation
of a problem space or domain.
– Performer: does something with the knowledge base to produce results
– Critic: evaluates results produced against expected results
– Learner: takes output from critic and modifies something in KB or performer.
• May also need a “problem generator” to test performance against.

7CSC 8520 Spring 2013. Paula Matuszek
A Very Simple Learning Program• Animals Guessing Game
– Representation is a binary tree– Performer is a tree walker interacting with a
human– Critic is the human player– Learning component elicits new questions and
modifies the binary tree

8CSC 8520 Spring 2013. Paula Matuszek
What Are We Learning?• Direct mapping from current state to
actions
• Way to infer relevant properties of the world from the current percept sequence
• Information about changes and prediction of results of actions
• Desirability of states and actions
• Goals

9CSC 8520 Spring 2013. Paula Matuszek
Representing The Problem
• Representing the problem to be solved is the first decision to be made in any machine learning application
• It’s also the most important.
• And the one that depends most on knowing the domain -- the field in which the problem is set.

10
CSC 8520 Spring 2013. Paula Matuszek
Representation• How do you describe your problem?
– I'm guessing an animal: binary decision tree
– I'm playing chess: the board itself, sets of rules for choosing moves
– I'm categorizing documents: vector of word frequencies for this document and for the corpus of documents
– I'm fixing computers: frequency matrix of causes and symptoms
– I'm OCRing digits: probability of this digit; 6x10 matrix of pixels; % light; # straight lines

CSC 8520 Spring 2013. Paula Matuszek 14
Performer• We are building a machine learning system because
we want to do something.– make a prediction
– sort into categories
– look for similarities
• The performer is the part of the system that actually does things.
• Once a system has learned, or been trained, this is the component we continue to use.
• It may be as simple as a formula to be applied, or it may be a complex program

12
CSC 8520 Spring 2013. Paula Matuszek
Performer• How do you take action?
– Guessing an animal: walk the tree and ask associated questions
– Playing chess: chain through the rules to identify a move; use conflict resolution to choose one; output it.
– Categorizing documents: apply a function to the vector of features (word frequencies) to determine which category to put document in
– Fixing computers: use known symptoms to identify potential causes, check matrix for additional diagnostic symptoms.
– OCRing digits: input the features for a digit, output probability that it's 0-9.

CSC 8520 Spring 2013. Paula Matuszek 16
Critic• This component provides the experience we
learn from.
• Typically, it is a set of examples with the decision that should be reached or action that should be taken
• But may be any kind of feedback that gives an indication of how close we are to where we want to be.

14
CSC 8520 Spring 2013. Paula Matuszek
Critic• How do you judge correct actions?
– Guessing an animal: human feedback
– Fixing computers: Human input about symptoms and cause observed for a specific case
– OCRing digits: Human-categorized training set.
– Categorizing documents: match to a set of human-categorized test documents.
– Categorizing documents: which are most similar in language or content?
– Playing chess: who won? (Credit assignment problem)
• Can be generally categorized as supervised, unsupervised, reinforcement.

15
CSC 8520 Spring 2013. Paula Matuszek
Supervised Learning• In supervised learning, we provide the system with
example training data and the result we want to see from those data. – each example, or training case, consists of a set of
variables or features describing one case, including the decision that should be made
– the system builds a model from the examples and uses the model to make a decision
– the critic compares the actual decision to the desired decision
– and tweaks the model to make the actual and desired decisions more similar

16
CSC 8520 Spring 2013. Paula Matuszek
Supervised Learning Examples• Learn to detect spam from example spam
and non-spam email
• Decide whether a house will sell from a list of its features
• Decide the age and gender of a skeleton

17
CSC 8520 Spring 2013. Paula Matuszek
Unsupervised Learning• In an unsupervised learning application, we do
not give the system any a priori decisions.• The task instead is to find similarities among the
examples given and group them• The critic is some measure of similarity among
the cases in a group compared to those in a different group
• The data we provide define the kind of similarities and groupings we will find.

18
CSC 8520 Spring 2013. Paula Matuszek
Unsupervised Learning• The goal in unsupervised learning is often
focused more on discovery than on specific decisions. Some examples:– do my search results have some natural
grouping? (eg, “bank” should give results related to finance and results related to rivers)
– can I identify categories or genres of books based on what people purchase?

19
CSC 8520 Spring 2013. Paula Matuszek
Reinforcement Learning• Reinforcement learning systems learn a
series of actions or decisions, rather than a single decision, based on feedback given at the end of the series.– For instance, the Animals game makes multiple
moves, but the critic gives only whether the game was won or lost.

CSC 8520 Spring 2013. Paula Matuszek 18
Learner• The learner is the core of a machine learning
system. It will– examine the information provided by the critic
– use it to modify the representation to move toward a more desirable action the next time.
– repeat until the performance is satisfactory, or until it stops improving
• There are many existing tools and systems which can be used here.

21
CSC 8520 Spring 2013. Paula Matuszek
Learner• What does the learner do?
– Guessing an animal: elicit a question from the user and add it to the binary tree
– Fixing computers: update frequency matrix with actual symptoms and outcome
– OCRing digits: modify weights on a network of associations.
– Categorizing documents: modify the weights on the function to improve categorization
– Playing chess: increase the weight for some rules and decrease for others.

22
CSC 8520 Spring 2013. Paula Matuszek
General Model of Learning AgentE
nvironment
Agent
Critic
Learning Element
Problem Generator
Performer with KB
Performance Standard
Sensors
Effectors
feedback
learning goals
changes
knowledge

23
CSC 8520 Spring 2013. Paula Matuszek
The Inputs• We defined learning as changes in behavior
based on experience.
• The nature of that experience is critical to the success of a learning system.
• In machine learning, that means we need to give careful attention to the examples we give the system to learn from.

24
CSC 8520 Spring 2013. Paula Matuszek
Representative Examples• Goal of our machine learning system is to
act correctly over some set of inputs or cases. This is the population or corpus it will be applied to.
• The machine learning examples must accurately reflect the field or domain that we want to learn. The examples must be typical of the population for which we will eventually make decisions.

25
CSC 8520 Spring 2013. Paula Matuszek
Typical Mistakes in Choosing Examples
• The “convenience” sample: – using the examples that are easy to get, whether or not they
reflect the cases we will make decisions on later.
• The positive examples: – using only examples with one of the two possible outcomes;
only loans made, for instance, not those denied
• The unbalanced examples– choosing different proportions of positive and negative
examples than the population. For instance, about 7% of mammograms show some abnormality. If you wanted to train a system to recognize abnormal mammogram films, you should not use 50% normal and 50% abnormal films as example.

26
CSC 8520 Spring 2013. Paula Matuszek
Are these good samples?• All email received in the last two days
• Every 10th test for strep received by a lab
• First 10,000 credit card acceptance records and first 10,000 credit card rejection records
• All incoming freshmen for Villanova in 2013
• Every 10th book at www.gutenberg.org

27
CSC 8520 Spring 2013. Paula Matuszek
Feature Spaces• We saw in knowledge representation that we
are always using an abstraction which omits detail
• Machine Learning is similar -- which features of our examples do we include?– They should be relevant to what we want to learn– They should ideally be observable for every
example– They should be independent of one another

28
CSC 8520 Spring 2013. Paula Matuszek
Relevant Features• We want our system to look at some features
and some decision, and find the patterns which led to the decision.
• This will only work if the features we give the system are in fact related to the decision being made.
• Examples:– To decide whether a house will sell
• Probably relevant: price, square footage, age
• Probably irrelevant: name of the owner, day of the week

29
CSC 8520 Spring 2013. Paula Matuszek
Which Are Relevant 1• To decide whether an illness is influenza
1. presence of fever
2. last name of patient
3. color of shoes
4. presence of cough
5. date

30
CSC 8520 Spring 2013. Paula Matuszek
Which Are Relevant 2
• Decide gender of a skeleton1. shape of pelvis
2. gender of the examiner
3. length of femur
4. date
5. number of ribs
6. position of bones

31
CSC 8520 Spring 2013. Paula Matuszek
Relevant Features• A supervised learning algorithm can use
the expected answer to ignore irrelevant features. but if the relevant ones aren’t included the system cannot perform well.
• For unsupervised systems, giving it only relevant features is critical.
• You must know your domain and have some feel for what matters to use these techniques successfully.

32
CSC 8520 Spring 2013. Paula Matuszek
Irrelevant Features: A Painful Example• There were about a ten million articles relevant
to medicine indexed in Medline in 2011; about 28,500 of them included diabetes.
• Clearly, if you are doing research about diabetes, you are not going to read them all.
• Medline provides a reference and abstract for each. Can we cluster them by giving this information to a machine learning system, and get some idea of the overall pattern of the research?

33
CSC 8520 Spring 2013. Paula Matuszek
Example Medline AbstractActa Diabetol. 2012 Nov 16. [Epub ahead of print]
Polymorphisms in the Selenoprotein S gene and subclinical cardiovascular disease in the Diabetes Heart Study.Cox AJ, Lehtinen AB, Xu J, Langefeld CD, Freedman BI, Carr JJ, Bowden DW.Source
Center for Human Genomics, Wake Forest School of Medicine, Winston-Salem, NC, USA.
AbstractSelenoprotein S (SelS) has previously been associated with a range of inflammatory markers, particularly in the context of cardiovascular disease (CVD). The aim of this study was to examine the role of SELS genetic variants in risk for subclinical CVD and mortality in individuals with type 2diabetes mellitus (T2DM). The association between 10 polymorphisms tagging SELS and coronary (CAC), carotid (CarCP) and abdominal aortic calcified plaque, carotid intima media thickness and other known CVD risk factors was examined in 1220 European Americans from the family-basedDiabetes Heart Study. The strongest evidence of association for SELS SNPs was observed for CarCP; rs28665122 (5' region; β = 0.329, p = 0.044), rs4965814 (intron 5; β = 0.329, p = 0.036), rs28628459 (3' region; β = 0.331, p = 0.039) and rs7178239 (downstream; β = 0.375, p = 0.016) were all associated. In addition, rs12917258 (intron 5) was associated with CAC (β = -0.230, p = 0.032), and rs4965814, rs28628459 and rs9806366 were all associated with self-reported history of prior CVD (p = 0.020-0.043). These results suggest a potential role for the SELS region in the development subclinical CVD in this sample enriched for T2DM. Further understanding the mechanisms underpinning these relationships may prove important in predicting and managing CVD complications in T2DM.
PMID: 23161441 [PubMed - as supplied by publisher]
http://www.ncbi.nlm.nih.gov/pubmed?term=Langefeld%20CD%5BAuthor%5D&cauthor=true&cauthor_uid=23161441
http://www.ncbi.nlm.nih.gov/pubmed?term=Langefeld%20CD%5BAuthor%5D&cauthor=true&cauthor_uid=23161441

34
CSC 8520 Spring 2013. Paula Matuszek
Diabetes clustering• Representation: the entire text of set of
Medline abstracts relevant to diabetes.
• Actor: Tool to display clusters of related documents
• Critic: a measure of how much vocabulary is in common between two abstracts
• Learner: a method which uses the critic to draw cluster boundaries such that the abstracts in a cluster have similar vocabularies

35
CSC 8520 Spring 2013. Paula Matuszek
Result• A good clustering tool created tight
clusters.
• But the vocabulary they mostly had in common was the abbreviated journal titles.– Acta Diabetol
• So all the clusters did was assign articles to journals. Useful sometimes, but not here
• Would have been better to omit title, date, authors, etc, and just include the actual text.

36
CSC 8520 Spring 2013. Paula Matuszek
Some data sets• These are included with the Weka
distribution.
• Most are drawn from the UC Irvine Machine Learning Repository at http://archive.ics.uci.edu/ml/

37
CSC 8520 Spring 2013. Paula Matuszek
Onward!• Okay, when we have a good sample and
good features, what do we do with them?

38
CSC 8520 Spring 2013. Paula Matuszek
The Inductive Learning Problem• Extrapolate from a given set of examples to
make accurate predictions about future examples
• Concept learning or classification– Given a set of examples of some
concept/class/category, determine if a given example is an instance of the concept or not
– If it is an instance, we call it a positive example
– If it is not, it is called a negative example
• Usually called supervised learning

39
CSC 8520 Spring 2013. Paula Matuszek
Inductive Learning Framework• Representation must extract from possible
observations a feature vector of relevant features for each example.
• The number of attributes and values for the attributes are fixed (although values can be continuous).
• Each example is represented as a specific feature vector, and is identified as a positive or negative instance.
• Each example can be interpreted as a point in an n-dimensional feature space, where n is the number of attributes

40
CSC 8520 Spring 2013. Paula Matuszek
Hypotheses• The task of a supervised learning system can be viewed
as learning a function which predicts the outcome from the inputs: – Given a training set of N example pairs (x1, y1) (x2,y2)...
(xn,yn), where each yj was generated by an unknown function y = f(x), discover a function h that approximates the true function y
• h is our hypothesis, and learning is the process of finding a good h in the space of possible hypotheses
• Prefer simplest consistent with the data
• Tradeoff between fit and generalizability
• Tradeoff between fit and computational complexity

41
CSC 8520 Spring 2013. Paula Matuszek
Decision Tree Induction• Very common machine learning and data
mining technique.
• Given:– Examples– Attributes– Goal (classification, typically)
• Pick “important” attribute: one which divides set cleanly.
• Recur with subsets not yet classified.

42
CSC 8520 Spring 2013. Paula Matuszek
Expressiveness• Decision trees can express any function of the input attributes.
• E.g., for Boolean functions, truth table row → path to leaf:
• Trivially, there is a consistent decision tree for any training set with one path to leaf for each example (unless f nondeterministic in x) but it probably won't generalize to new examples
• Prefer to find more compact decision trees

43
CSC 8520 Spring 2013. Paula Matuszek
ID3• A greedy algorithm for decision tree construction
originally developed by Ross Quinlan, 1987
• Top-down construction of decision tree by recursively selecting “best attribute” to use at the current node in tree– Once attribute is selected, generate children nodes, one
for each possible value of selected attribute
– Partition examples using possible values of attribute, assign subsets of examples to appropriate child node
– Repeat for each child node until all examples associated with a node are either all positive or all negative

44
CSC 8520 Spring 2013. Paula Matuszek
Best Attribute• What’s the best attribute to choose? The
one with the best information gain– If we choose Bar, we have
• no: 3 -, 3 + yes: 3 -, 3+
– If we choose Hungry, we have• no: 4-, 1 + yes: 1 -, 5+
– Hungry has given us more information about the correct classification.

45
CSC 8520 Spring 2013. Paula Matuszek
Textbook restaurant domain• Develop a decision tree to model the decision a
patron makes when deciding whether or not to wait for a table at a restaurant
• Two classes: wait, leave
• Ten attributes: Alternative available? Bar in restaurant? Is it Friday? Are we hungry? How full is the restaurant? How expensive? Is it raining? Do we have a reservation? What type of restaurant is it? What’s the purported waiting time?
• Training set of 12 examples
• ~ 7000 possible cases

46
CSC 8520 Spring 2013. Paula Matuszek
Thinking About It• What might you expect a decision tree to
have as the first question? The second?

47
CSC 8520 Spring 2013. Paula Matuszek
A Decision Tree from Introspection

48
CSC 8520 Spring 2013. Paula Matuszek
A Training Set
49
CSC 8520 Spring 2013. Paula Matuszek
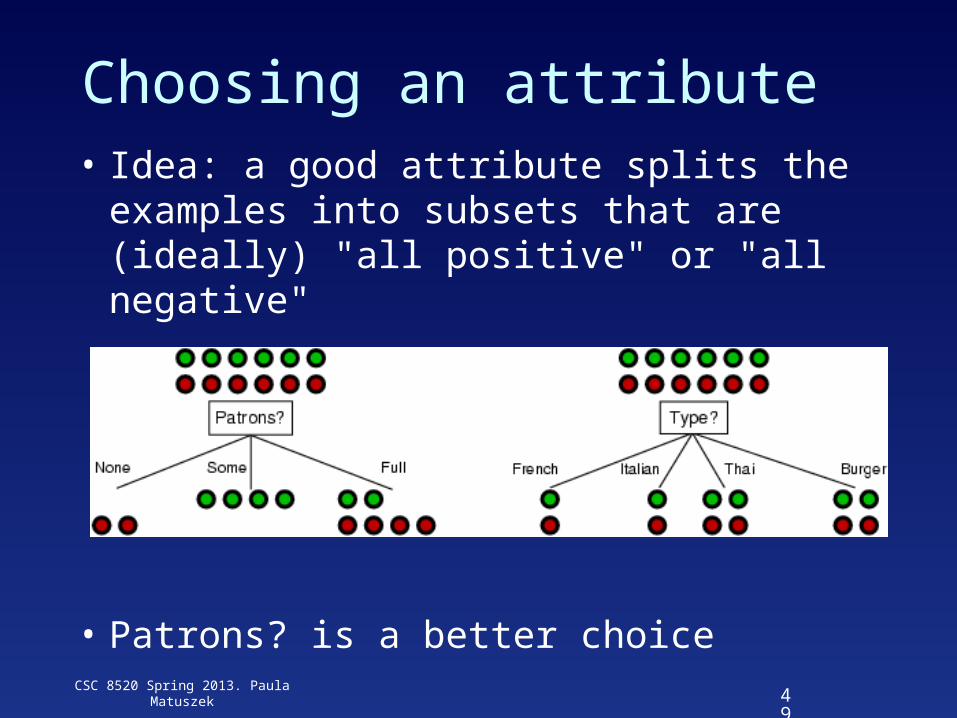
Choosing an attribute• Idea: a good attribute splits the examples
into subsets that are (ideally) "all positive" or "all negative"
• Patrons? is a better choice

50
CSC 8520 Spring 2013. Paula Matuszek
Learned Tree

51
CSC 8520 Spring 2013. Paula Matuszek
How well does it work?• Many case studies have shown that decision
trees are at least as accurate as human experts. – A study for diagnosing breast cancer had humans
correctly classifying the examples 65% of the time; the decision tree classified 72% correct
– British Petroleum designed a decision tree for gas-oil separation for offshore oil platforms that replaced an earlier rule-based expert system
– Cessna designed an airplane flight controller using 90,000 examples and 20 attributes per example

52
CSC 8520 Spring 2013. Paula Matuszek
Evaluating Classifiers• With a decision tree, or with any classifier,
we need to know how well our trained model performs on other data
• Train on sample data, evaluate on test data (why?)
• Some things to look at:– classification accuracy: percent correctly
classified
– confusion matrix
– sensitivity and specificity

53
CSC 8520 Spring 2013. Paula Matuszek
Evaluating Classifying Systems• Standard methodology:
– 1. Collect a large set of examples (all with correct classifications)
– 2. Randomly divide into two disjoint sets: training and test
– 3. Apply learning algorithm to training set
– 4. Measure performance with respect to test set
• Important: keep the training and test sets disjoint!
• To study the efficiency and robustness of an algorithm, repeat steps 2-4 for different training sets
• If you modify your algorithm, start again with step 1 to avoid evolving the algorithm to work well on just this collection

54
CSC 8520 Spring 2013. Paula Matuszek
Confusion Matrix
Is it spam? Predicted yes
Predicted no
Actually yes
True positives
False negatives
Actually no
False positives
True negatives
Note that “positive” vs “negative” is arbitrary

55
CSC 8520 Spring 2013. Paula Matuszek
Specificity and Sensitivity• sensitivity: ratio of labeled positives to
actual positives– how much spam are we finding?
• specificity: ratio of labeled negatives to actual negatives– how much “real” email are we calling email?

56
CSC 8520 Spring 2013. Paula Matuszek
More on Evaluating Classifiers• Overfitting: very close fit to training data
which takes advantage of irrelevant variations in instances– performance on test data will be much lower– may mean that your training sample isn’t
representative
• Is the classifier actually useful?– Compare to the “majority” classifier

57
CSC 8520 Spring 2013. Paula Matuszek
Concept Check• For binary classifiers A and B, for balanced data:
– Which is better: A is 80% accurate, B is 60% accurate
– Which is better: A has 90% sensitivity, B has 70% sensitivity
– Which is the better classifier:• A has 100 % sensitivity, 50% specificity
• B has 80% sensitivity, 80% specificity
• Would you use a spam filter that was 80% accurate?
• Would you use a classifier for who needs major surgery that was 80% accurate?
• Would you ever use a binary classifier that is 50% accurate?

58
CSC 8520 Spring 2013. Paula Matuszek
Pruning• With enough levels of a decision tree we
can always get the leaves to be 100% positive or negative
• But if we are down to one or two cases in each leaf we are probably overfitting
• Useful to prune leaves; stop when– we reach a certain level– we reach a small enough size leaf– our information gain is increasing too slowly

59
CSC 8520 Spring 2013. Paula Matuszek
Strengths of Decision Trees• Strengths include
– Fast to learn and to use
– Simple to implement
– Can look at the tree and see what is going on -- relatively “white box”
– Empirically valid in many commercial products
– Handles noisy data (with pruning)
• C4.5 and C5.0 are extension of ID3 that account for unavailable values, continuous attribute value ranges, pruning of decision trees, rule derivation.

60
CSC 8520 Spring 2013. Paula Matuszek
Weaknesses and Issues• Weaknesses include:
– Univariate splits/partitioning (one attribute at a time) limits types of possible trees
– Large decision trees may be hard to understand– Requires fixed-length feature vectors – Non-incremental (i.e., batch method)– Overfitting

61
CSC 8520 Spring 2013. Paula Matuszek
Decision Tree Architecture• Knowledge Base: the decision tree itself.
• Performer: tree walker
• Critic: actual outcome in training case
• Learner: ID3 or its variants– This is an example of a large class of learners
that need all of the examples at once in order to learn. Batch, not incremental.

62
CSC 8520 Spring 2013. Paula Matuszek
Strengths of Decision Trees• Strengths include
– Fast if the data set isn’t too large– Simple to implement– Often produces simpler tree than human experts– Output is reasonably understandable by humans– Empirically valid in many commercial products– Handles noisy data

63
CSC 8520 Spring 2013. Paula Matuszek
Decision Tree Weaknesses• Weaknesses include:
– Univariate splits/partitioning (one attribute at a time) limits types of possible trees
– Large decision trees may be hard to understand– Requires fixed-length feature vectors – Non-incremental (i.e., batch method)– For continuous or real-valued features requires
additional complexity to choose decision points

64
CSC 8520 Spring 2013. Paula Matuszek
Summary: Decision tree learning• One of most widely used learning methods
in practice
• Can out-perform human experts in many problems


















