
1 CS 525 Advanced Distributed Systems Spring 09 Indranil Gupta Lecture 7 More on Epidemics (or...
40
1 CS 525 Advanced Distributed Systems Spring 09 Indranil Gupta Lecture 7 More on Epidemics (or “Tipping Point Protocols”) February 12, 2009 (gatorlog.com) (epath.org)
-
Upload
margaretmargaret-dorsey -
Category
Documents
-
view
225 -
download
0
Transcript of 1 CS 525 Advanced Distributed Systems Spring 09 Indranil Gupta Lecture 7 More on Epidemics (or...

1
CS 525 Advanced Distributed Systems
Spring 09
Indranil GuptaLecture 7
More on Epidemics (or “Tipping Point Protocols”)February 12, 2009
(gatorlog.com)(epath.org)
2
Question…What fraction of main roads need to be randomly knocked out before source and destination are completely cut off?
Destination
Source

3
Critical Value? Answer = 0.5
Tipping Point!
Source
Destination
(Comes from Percolation Theory)

4
“Tipping Point”
[Malcolm Gladwell, The Tipping Point, Little Brown and Company, ISBN: 0316346624]
Tipping is that (magic) moment when an idea, trend or social behavior crosses a threshold, and spreads like wildfire.

5
Epidemic Protocols
• A specific class of tipping point protocols• Local behavior at each node – probabilistic• Determines global, emergent behavior at the scale of the
distributed system• As one tunes up the local probabilities, the global
behavior may undergo a threshold behavior (or, a phase change)
• Three papers:1. Epidemic algorithms2. Bimodal multicast3. PBBF (sensor networks)

6
Epidemic Algorithms for Replicated Database Maintenance
Alan Demers et. al.
Xerox Palo Alto Research Center
PODC 1987
[Some slides borrowed from presentation by: R. Ganti and P. Jayachandran]

7
Introduction
• Maintain mutual consistency of updates in a distributed and replicated database
• Used in Clearinghouse database – developed in Xerox PARC and used for many years
• First cut approaches – Direct mail: send updates to all nodes
• Timely and efficient, but unreliable
– Anti-entropy: exchange database content with random site • Reliable, but slower than direct mail and uses more resources
– Rumor mongering: exchange only ‘hot rumor’ updates• Less reliable than anti-entropy, but uses fewer resources

8
Epidemic Multicast
Protocol Protocol roundsrounds (local clock) (local clock)
b b random targets per roundrandom targets per round
UninfectedUninfected
InfectedInfected
Gossip Message (UDP)Gossip Message (UDP)
(from Lecture 1)

9
Epidemic Multicast (Push)
Protocol Protocol roundsrounds (local clock) (local clock)
b b random targets per roundrandom targets per round
UninfectedUninfected
InfectedInfected
Gossip Message (UDP)Gossip Message (UDP)

10
Epidemic Multicast (Pull)
Protocol Protocol roundsrounds (local clock) (local clock)
b b random targets per roundrandom targets per round
UninfectedUninfected
InfectedInfected
Gossip Message (UDP)Gossip Message (UDP)

11
Pull > Push
• Pull converges faster than push, thus providing better delay
• Push-pull hybrid variant possible (see Karp and Shenker’s “Randomized Rumor Spreading”)
p i 1 p i2
p i 1 p i 11n
n 1 p i
Pull
Push
pi – Probability that a node is susceptible after the ith round

12
Anti-entropy: Optimizations
• Maintain checksum, compare databases if checksums unequal
• Maintain recent update lists for time T, exchange lists first
• Maintain inverted index of database by timestamp; exchange information in reverse timestamp order, incrementally re-compute checksums

13
Epidemic Flavors
• Blind vs. Feedback– Blind: lose interest to gossip with probability 1/k every
time you gossip
– Feedback: Loss of interest with probability 1/k only when recipient already knows the rumor
• Counter vs. Coin– Coin: above variants
– Counter: Lose interest completely after k unnecessary contacts. Can be combined with blind.
• Push vs. Pull

14
Deletion and Death Certificates• Absence of item does not spread; On the contrary, it
can get resurrected!• Use of death certificates (DCs) – when a node
receives a DC, old copy of data is deleted• How long to maintain a DC?
– Typically twice (or some multiple of) the time to spread the information
– Alternately, use Chandy and Lamport snapshot algorithm to ensure all nodes have received
– Certain sites maintain dormant DCs for a longer duration; re-awakened if item seen again

15
Performance Metrics
• Residue: Fraction of susceptibles left when epidemic finishes
• Traffic: (Total update traffic) / (No. of sites)
• Delay: Average time for receiving update and maximum time for receiving update
• Some results:– Counters and feedback improve delay– Pull provides lower delay than push

16
Performance Evaluation
Tipping Point Behavior

17
Discussion
Pick your favorite:• Push vs. pull vs. push-pull
– Name one disadvantage of each
• Direct mail vs. anti-entropy vs. rumor mongering– Name one disadvantage of each
• Random neigbhor picking– Disadvantage in wired networks?
– In Sensor network?

18
Bimodal Multicast
Kenneth P. Birman et. al.
ACM TOCS 1999
[Some slides borrowed from presentation by: W. Fagen and L. Cook]

19
“Traditional” Multicast Protocols

20
Vs. Pbcast
• Atomicity: All or none delivery
• Multicast stability: Reliable immediately delivery of messages
• Scalability: Bad. Costs >= quadratic with group size.
• Ordering
• Atomicity: Bimodal delivery guarantee, almost all or almost none (immediately)
• Multicast stability: Reliable eventual delivery of messages
• Scalability: Costs logarithmic w.r.t. network size. Throughput stability.
• Ordering
Traditional Multicast Pbcast

21
Pbcast: Probabilistic Broadcast Protocol
• Pbcast has two stages:1. Unreliable, hierarchical, best-effort broadcast.
Eg. IP Multicast
2. Two-phase anti-entropy protocol: runs simultaneously with the broadcast messages
• First phase detects message loss
• Second phase corrects such losses

22
The second stage
• Anti-entropy round:– Gossip Messages:
• Each process chooses another random process and sends a summary of its recent messages
– Solicitation Messages:• Messages sent back to the sender of the gossip message requesting a
resend of a given set of messages (not necessarily the original source)– Message Resend:
• Upon reception of a solicitation message, the sender resends that message
• Protocol parameters at each node– # of rounds and # of processes contacted in each round– Product of above two parameters called fanout

23
Optimizations
• Soft-Failure Detection: Retransmission requests served only if received recently; protects against congestion caused due to redundant retransmissions
• Round Retransmission Limit: Limit the no. of retransmissions in a round; spread overhead in space and time
• Most-Recent-First Retransmission: prefer recent messages
• Independent Numbering of Rounds: Allows delivery and garbage collection to be entirely a local decision
• Multicast for Some Retransmissions

24
Bimodality of Pbcast
Almost none Almost all
LogarithmicY-axis

25
Latency for Delivery
Logarithmic growth
26
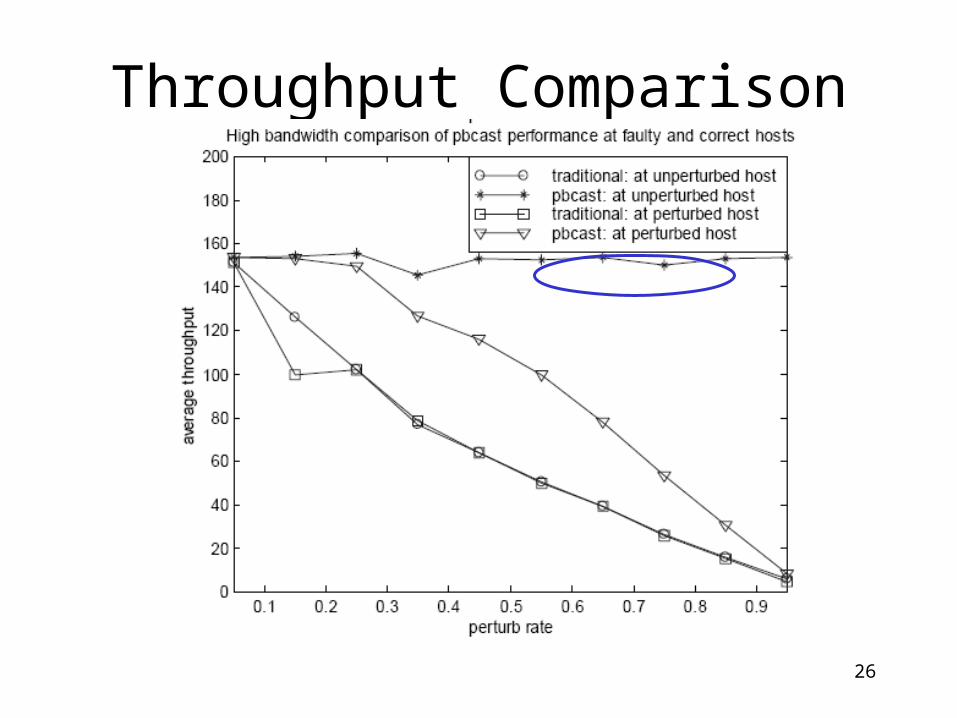
Throughput Comparison

27
Discussion
• Disadvantages of Bimodal Multicast?– When would wasteful messages be sent?
• What happens when– Rate of injection of multicasts is very very low?– IP multicast is very very reliable?– IP multicast is very very unreliable?

28
PBBF: Probability-Based Broadcast Forwarding
Cigdem Sengul and Matt Miller
ICDCS 2005 and ACM TOSN 2008
(Originated from a 525 Project)

29
Broadcast in an Ad-Hoc Network• Ad-hoc sensor network (Grid example below)• One node has a piece of information that it needs to broadcast: e.g., (1)
code update, (2) query• Simple approach: each node floods received message to all its neighbors
– Disadvantages?

30
IEEE 802.11 PSM
A real, stable MAC protocol (similar results for S-MAC, T-MAC, etc.)
• Nodes are assumed to be synchronized• Every beacon interval (BI), all nodes wake up for
an ATIM window (AW)• During the AW, nodes advertise any traffic that
they have queued• After the AW, nodes remain active if they expect
to send or receive data based on advertisements; otherwise nodes return to sleep until the next BI

31
Protocol Extreme #1
A
N1
N2
N3
D
A = ATIM Pkt
D = Data Pkt
N2N1 N3
A
D
A

32
Protocol Extreme #2
N1
N2
N3
D
A = ATIM Pkt
D = Data Pkt
D
D
A
N2N1 N3

33
Probability-Based Broadcast Forwarding (PBBF)
• Introduce two parameters to sleep scheduling protocols: p and q
• When a node is scheduled to sleep, it will remain active with probability q
• When a node receives a broadcast, it rebroadcasts immediately with probability p– With probability (1-p), the node will wait and
advertise the packet during the next AW before rebroadcasting the packet

34
Analysis: Reliability• Phase transition
when:
pq + (1-p) ≈ 0.8-0.85• Larger than
traditional bond percolation threshold– Boundary effects
– Different metric
• Still shows phase transition
qp=
0.25
p=0.
37
p=0.
5
p=0.
75
Fra
ctio
n of
Bro
adca
sts
Rec
eive
d by
99%
of
Nod
es
Tipping Point!

35
Application: Energy and LatencyEnergy
Joules/Broadcast
q
LatencyAverage 5-Hop Latency
PBBF
Increasing p
q≈ 1 + q * [(BI - AW)/AW]
Ns2 simulation: 50 nodes, uniform placement, 10 avg. neighbors

36
Adaptive PBBFE
nerg
y
Latency
Achievable Region

37
Adaptive PBBF (TOSN paper)• Dynamically adjusting p
and q to converge to user-specified QoS metrics– Code updates prefer
reliability overl latency– Queries prefer latency
over reliability
• Can specify any 2 of energy, latency, and reliability
• Subject to those constraints, p and q are adjusted to achieve the highest reliability possible Time
0.0
1.0
0.5q
p

38
Discussion
• PBBF: bond percolation (remove roads from city)• Haas et al paper (Infocom): site percolation
– Remove intersections/junctions (not roads) from city
• Site percolation and bond percolation have different thresholds and behaviors
• Hybrid possible? (like push-pull?)• What about over-hearing optimizations? (like
feedback)

39
Question…Are there other tipping point protocols…?
Destination
Source

40
Next Week Onwards
• Student Presentations start (see instructions)
• Reviews needed (see instructions)
• Project Meetings start (see newsgroup)– Think about which testbed you need access to:
PlanetLab, Emulab, Cirrus
• Tomorrow: Yahoo! Training seminar


















