
1 Bellman: A Data Quality Browser Tamraparni Dasu Theodore Johnson S. Muthukrishnan Vladislav...
30
1 Bellman: A Data Quality Browser Tamraparni Dasu Theodore Johnson S. Muthukrishnan Vladislav Shkapenyuk Amit Marathe Contact: [email protected]
-
date post
20-Dec-2015 -
Category
Documents
-
view
216 -
download
0
Transcript of 1 Bellman: A Data Quality Browser Tamraparni Dasu Theodore Johnson S. Muthukrishnan Vladislav...

1
Bellman: A Data Quality Browser
Tamraparni DasuTheodore JohnsonS. Muthukrishnan
Vladislav ShkapenyukAmit Marathe
Contact: [email protected]

2
Exploring Large and Complex Databases
• AT&T has a lot of large databases.– Many types of offerings (business/consumer/hosting, voice:
LD/local, data: frame/ip/vpn/voip, etc).– Many aspects of providing a service
(sales/provisioning/billing/network maintenance/customer care).– Many databases, each with 100’s to 1000’s of tables.
• These databases are complex– Legacy systems and procedures (AT&T is an old company).– AT&T’s scale requires local autonomy.
• Different conventions and encodings in different domains
– Complex interdependencies.• A user’s order touches many databases at some point or other.
• A customer may order many types of services, etc.

3
Our Problem• We provide special consulting services to AT&T
Business units.– Data mining studies.– Targeted data cleanup.– Help with large scale database integration and
cleanup efforts.
• “Special services” means that we are always looking at new data sets.– ODBC access to databases.– Web scraping– Delimited ascii dumps.
• We need help …

4
What is Bellman?• A “data quality browser”• A platform for integrating both simple and
advanced data browsing tools.• A platform for integrating data browsing and data
cleanup tools.• A platform for browsing and correlating multiple
disparate databases and data sets.
• Current status: the platform and the tools are in good shape, the UI and integration could use some work.

5
Database Profiling
• Collect summaries of the tables, fields, and data in the databases.
• Store in a supplementary database.• Use these summaries to
– Supplement database browsing.– Answer sophisticated queries about database
structure.– Support data mining on the database structure.

6
Bellman History
• Java-Bellman (first version)– Java/JDBC client software.– Collect profiles using C++/ODBC
• Oracle, Sybase, Teradata, Informix, SQL Server
– Problem : installation is difficult, especially to configure the ODBC drivers.
• Web-Bellman (current version)– ASP .NET/C# front end, C++ profiling.– No client software installation required.– Centralized management of ODBC drivers
and some advanced tools.

7
Bellman Screen Shots
• Bellman is best shown through some examples.
• Problem: – Its only interesting with real databases.– But the data is AT&T Proprietary
• We’ll do our best to show Bellman without getting ourselves fired.

8
Development site
Bellman is the browser
Spider is an applicationof our approximate stringmatching tools.
9
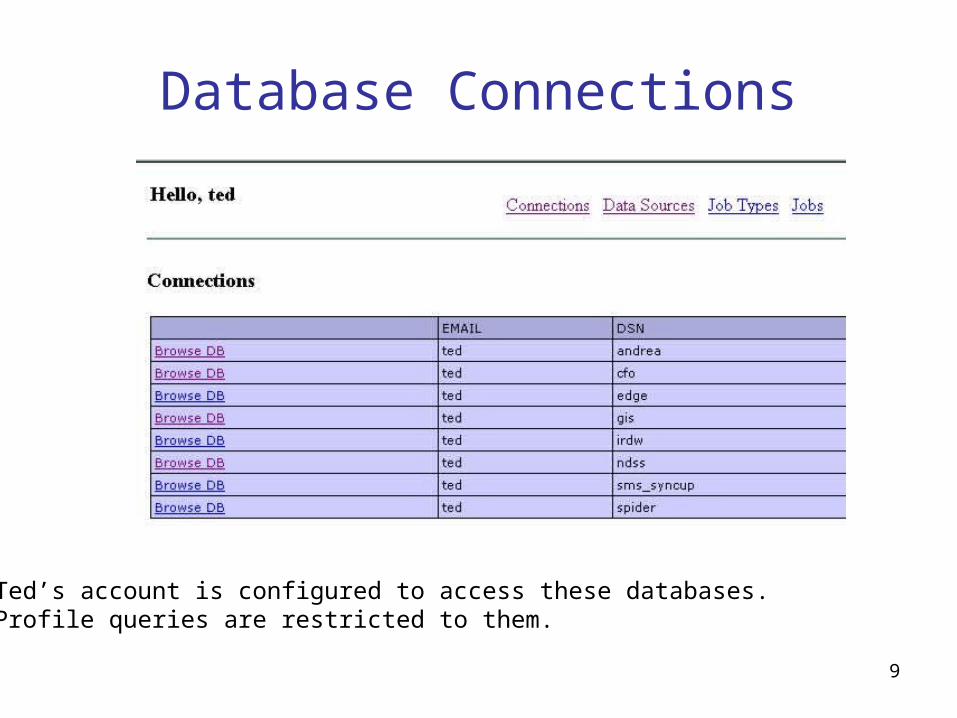
Database Connections
Ted’s account is configured to access these databases.Profile queries are restricted to them.
10
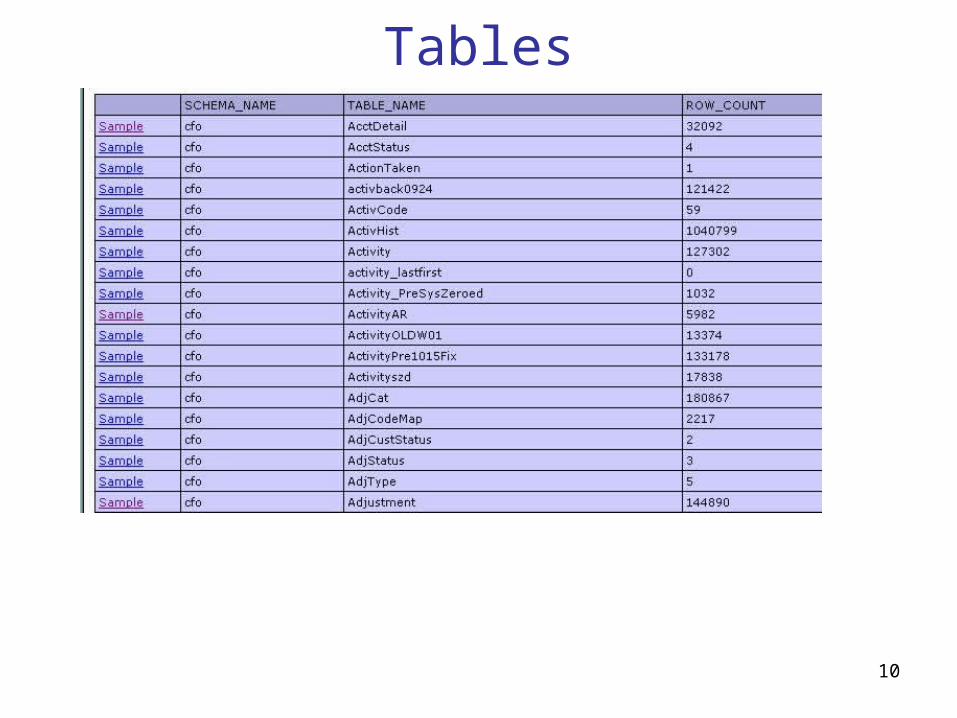
Tables
11
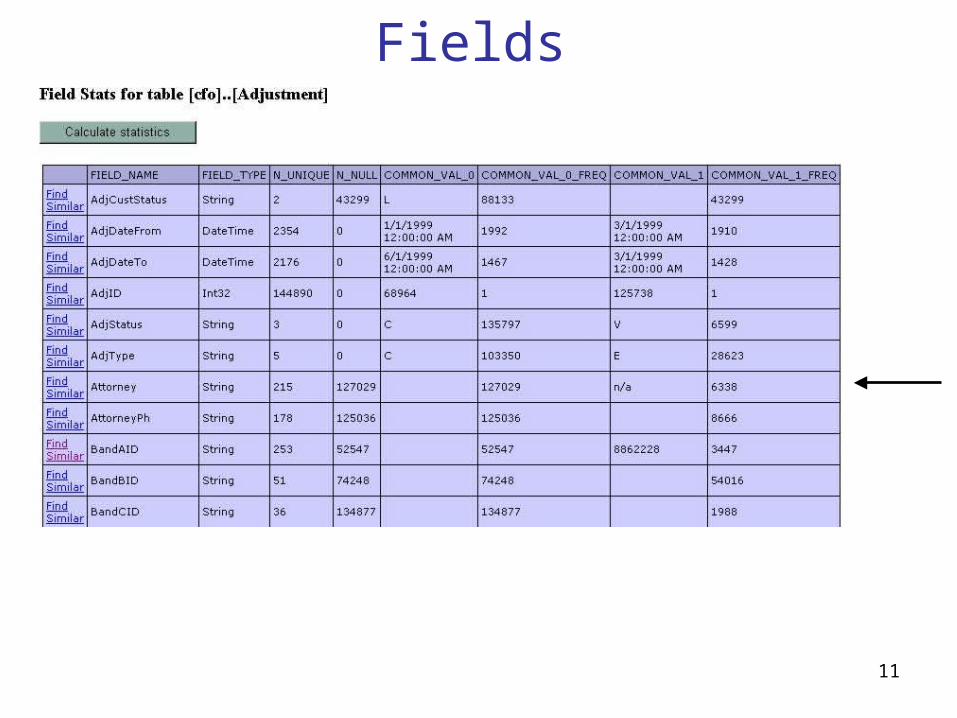
Fields

12
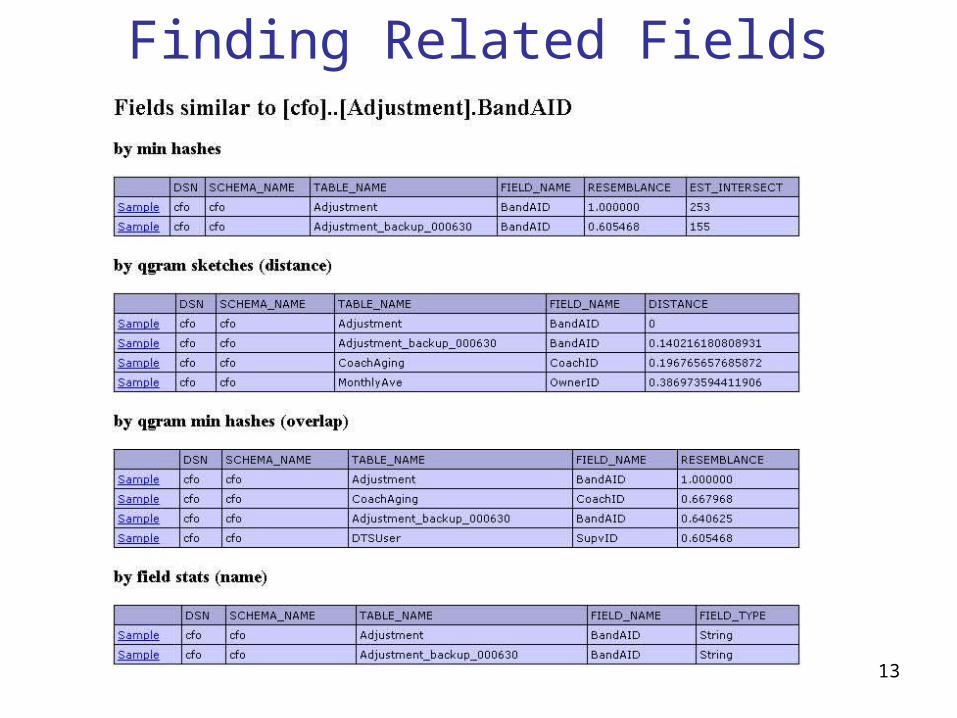
Find Similar
• What other fields in the database contain similar data?– Many values in common (exact match) : resemblance– “Textually similar”
• Many q-grams in common• Distribution of q-grams is similar.
– The fields have a similar name.
• Uses– Finding join paths– Finding join paths which require field transforms– Finding other fields with names/IDs/etc.
13
Finding Related Fields

14
A Comparison
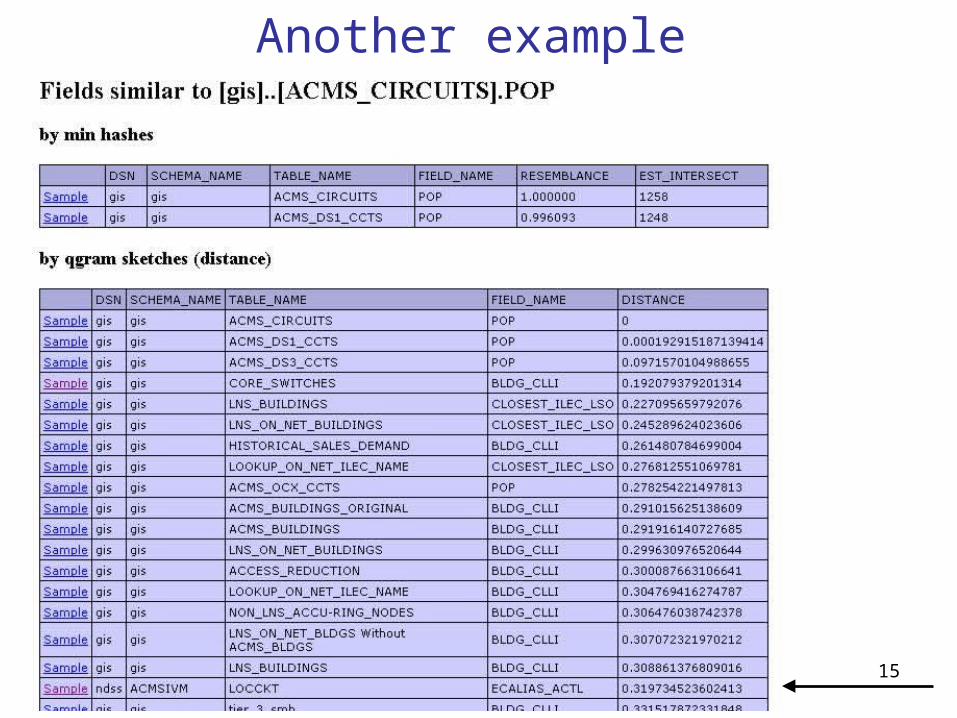
15
Another example
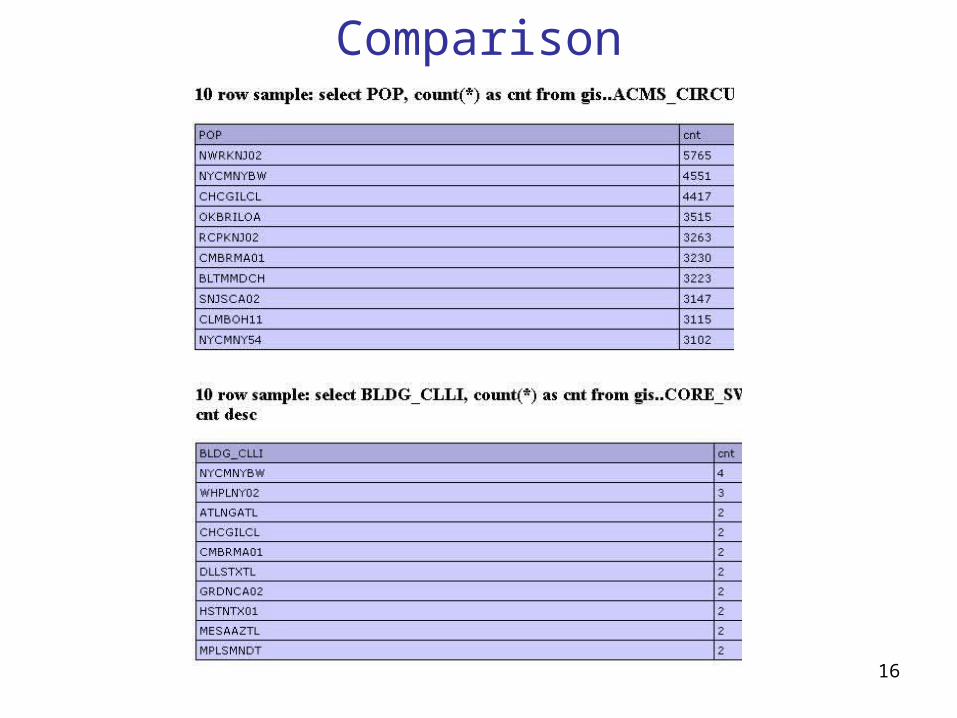
16
Comparison
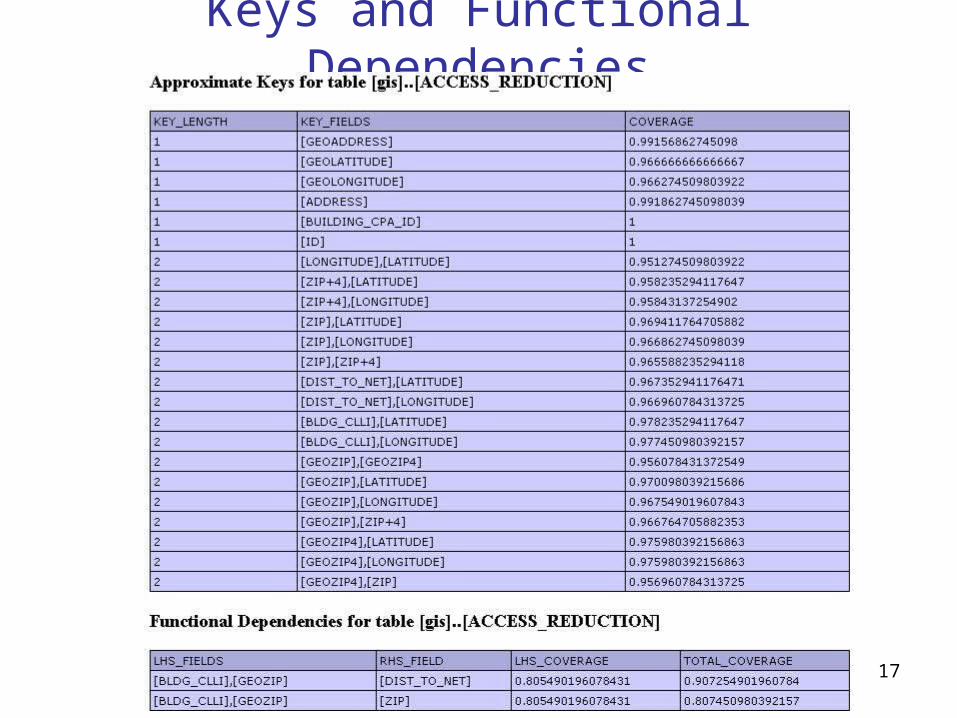
17
Keys and Functional Dependencies
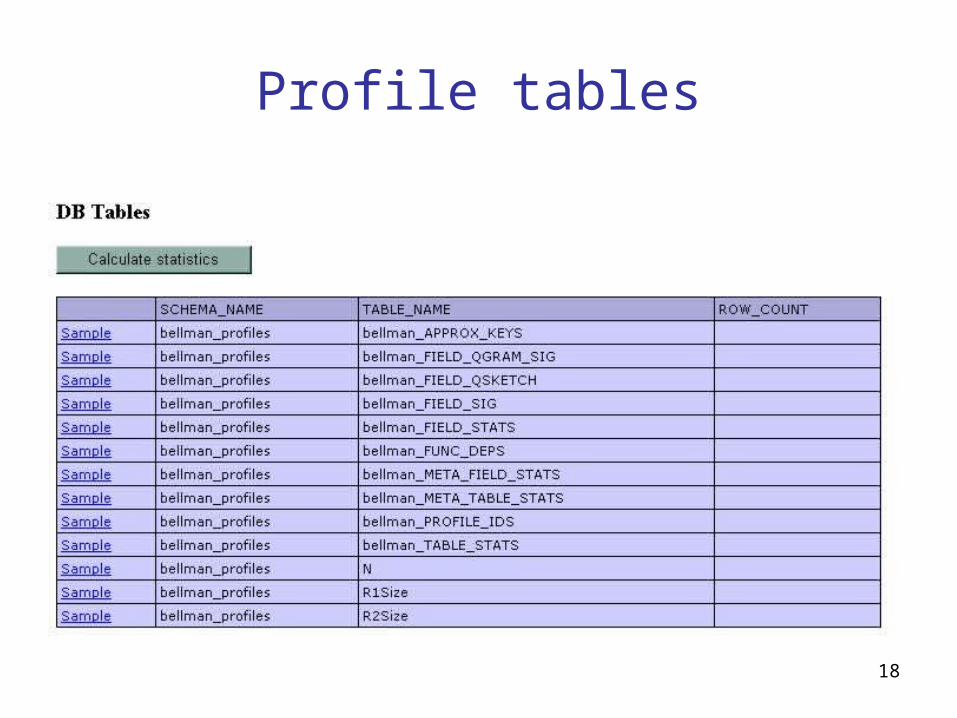
18
Profile tables

19
Algorithms
• Field similarity by exact match– Min Hash signatures to compute resemblance
• Field similarity by substring similarity– Resemblance of q-grams– Distribution of q-grams
• Efficient key finding

20
Set Resemblance
• The resemblance of two sets A, B is, |A
• After some algebra, we find that |A,(|A|+|B|)/(1+
,)• There are fast algorithms to compute …• Application to Bellman
– The sets in question are the unique values in the fields
– The resemblance of two fields is a good measure of their similarity.

21
Min Hash Signatures• h(a) is a hash function.• m(A) = min(h(a), a in A).
• Observation:Pr[m(A) = m(B)] = ,
• Why?– Universe restricted to AB– Equality only in AB
• Repeat the experiment many times.
• Signature:(m1(A), m2(A), …, mk(A))
A
B
ignoredm(A)<m(B)
m(A)>m(B)
m(A)=m(B)

22
Min Hash Implementation
• (Schema, Table, Field) maps to unique ID• 256 hash functions• Bellman_Field_Sig table has the schema
(ID, HashNum, MinHash)• MinHash is a 32-bit integer (collisions become an issue
for large sets)

23
Min Hash Implementation (cont.)
• SQL to find fields similar to field w/ ID 23 select S2.ID, count(*)
from Bellman_Field_Sig S1, Bellman_Field_Sig S2
where S1.ID=23 and
S1.HashNum = S2.HashNum and S1.MinHash=S2.MinHash
group by S2.ID
order by count(*) desc

24
Textual similarity
• Q-gram : collection of consecutive q-letter substrings.
• Example: 3-grams of “Bellman”– Bel, ell, llm, lma, man
• Q-gram resemblance : compute signatures of the set of q-grams of a field instead of field values.
• Q-gram similarity : L2 distance of the frequency distribution of the q-grams of a field.– Use sketches to store a compact approximate
summary of the q-gram distribution.

25
Q-gram Sketches
• V is a d dimensional vector• Sk(V) is the k dimensional vector (V.X1, V.X2, …, V.Xk) where Xi are random d dimensional vectors• Typically, k << d• L2(V1, V2) is approximated by L2(Sk(V1), Sk(V2))

26
Q-gram Sketch Implementation
• 256 random sketch vectors• Bellman_Field_QSketch
(ID, SkNum, SkVal)• Tuples correspnding to a particular ID constitute the
normalized sketch vector for that field• SkVal has datatype float

27
Q-gram Sketch Implementation
• SQL to find fields similar to field w/ ID 23 select S2.ID, sum((S1.SkVal – S2.SkVal) ** 2)
from Bellman_Field_QSketch S1, Bellman_Field_QSketch S2
where S1.ID = 23
and S1.SkVal = S2.SkVal
group by S2.ID
order by sum((S1.SkVal – S2.SkVal) ** 2) desc

28
Finding Keys
• Key a (minimal) set of fields whose composite value is unique in every record.
• Problem: finding all keys of length up to k in a table with F fields requires O(Fk) expensive count distinct queries.
• Solution:– Eliminate “bad” fields : floats, mostly NULL, etc.– Collect an in-memory sample
• Can store hashes of long strings.
– Compute count distinct queries on the sample• Verify keys by query against database
– Use Tane-style level-wise pruning.

29
Finding Keys (cont.)
• Upto 4-way keys found by Bellman• Candidate-1 keys are all the “good” fields• In iteration i+1, consider the cross product of candidate-i
keys and candidate-1 keys• Classify each set of i+1 fields so obtained as an
approximate key, candidate-(i+1) key or a functional dependency.
• Thresholds: key_threshold, min_improvement

30
Reference
• Mining Database Structure: Or, How to Build a Data Quality Browser – Dasu, Johnson, Muthukrishnan, Shkapenyuk, ACM SIGMOD 2002.


















