
Андрей Кутузов, Mail.Ru Group. Нейронные языковые модели и...
101
-
Upload
mailru-group -
Category
Science
-
view
910 -
download
4
Transcript of Андрей Кутузов, Mail.Ru Group. Нейронные языковые модели и...

Нейронные языковые модели
и задача определения семантической близости слов
для русского языка
Андрей Кутузов
Mail.ru Group
4 сентября 2015Moscow Data Science Meetup

План
1 Зачем семантическая близость?
2 Настало время нейронных моделей
3 Описание соревнования
4 Использованные корпуса
5 Оценка качества
6 Крутим ручки: важность гиперпараметров
7 Русский национальный корпус неожиданно выигрывает
8 Что ещё можно делать с дистрибутивно-семантическими моделями
9 Узнать больше
10 Вопросы
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 2
/ 43

Зачем семантическая близость?
TL;DR
1 Нейронные языковые модели (NNLM) без скрытого слоя успешнорешают задачу определения семантической близости слов длярусского языка.
2 Национальный корпус русского языка (НКРЯ,http://ruscorpora.ru) оказался одним из лучших обучающихкорпусов для этой задачи;
3 Наши модели, натренированные с разными параметрами и наразных корпусах, доступны для скачивания.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 3
/ 43

Зачем семантическая близость?
TL;DR
1 Нейронные языковые модели (NNLM) без скрытого слоя успешнорешают задачу определения семантической близости слов длярусского языка.
2 Национальный корпус русского языка (НКРЯ,http://ruscorpora.ru) оказался одним из лучших обучающихкорпусов для этой задачи;
3 Наши модели, натренированные с разными параметрами и наразных корпусах, доступны для скачивания.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 3
/ 43

Зачем семантическая близость?
TL;DR
1 Нейронные языковые модели (NNLM) без скрытого слоя успешнорешают задачу определения семантической близости слов длярусского языка.
2 Национальный корпус русского языка (НКРЯ,http://ruscorpora.ru) оказался одним из лучших обучающихкорпусов для этой задачи;
3 Наши модели, натренированные с разными параметрами и наразных корпусах, доступны для скачивания.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 3
/ 43

Зачем семантическая близость?
TL;DR
1 Нейронные языковые модели (NNLM) без скрытого слоя успешнорешают задачу определения семантической близости слов длярусского языка.
2 Национальный корпус русского языка (НКРЯ,http://ruscorpora.ru) оказался одним из лучших обучающихкорпусов для этой задачи;
3 Наши модели, натренированные с разными параметрами и наразных корпусах, доступны для скачивания.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 3
/ 43

Зачем семантическая близость?
Веб-сервис дистрибутивно-семантических моделей для русского
Сайт НКРЯ называется RusCorpora (”русские корпуса“ по-латыни).Чтобы выразить им признательность, мы запустили сервисRusVector es (”русские вектора“ всё на той же латыни)
http://ling.go.mail.ru/dsm
Можно развлечься во время доклада :-)
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 4
/ 43

Зачем семантическая близость?
Веб-сервис дистрибутивно-семантических моделей для русского
Сайт НКРЯ называется RusCorpora (”русские корпуса“ по-латыни).Чтобы выразить им признательность, мы запустили сервисRusVector es (”русские вектора“ всё на той же латыни)
http://ling.go.mail.ru/dsm
Можно развлечься во время доклада :-)
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 4
/ 43

Зачем семантическая близость?
Ценно само по себе: для генерации синонимов или “почтисинонимов” для расширения запросов или иных нужд.
Построение ‘семантической карты’ интересующего нас языка.
Удобно использовать для оценки качества семантических моделейвообще.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 5
/ 43

Зачем семантическая близость?
Ценно само по себе: для генерации синонимов или “почтисинонимов” для расширения запросов или иных нужд.
Построение ‘семантической карты’ интересующего нас языка.
Удобно использовать для оценки качества семантических моделейвообще.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 5
/ 43

Зачем семантическая близость?
Ценно само по себе: для генерации синонимов или “почтисинонимов” для расширения запросов или иных нужд.
Построение ‘семантической карты’ интересующего нас языка.
Удобно использовать для оценки качества семантических моделейвообще.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 5
/ 43
Зачем семантическая близость?
Итак, что такое “семантическая близость”?
Точнее, что такое лексическая близость?
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 6
/ 43

Зачем семантическая близость?
Итак, что такое “семантическая близость”?
Точнее, что такое лексическая близость?
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 6
/ 43

Зачем семантическая близость?
Итак, что такое “семантическая близость”?
Точнее, что такое лексическая близость?
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 6
/ 43
Зачем семантическая близость?
Как представить значение слова?
Семантика успешно сопротивляется попыткам формальногопредставления.
Чтобы понять, какие слова семантически близки, необходимопридумать машиночитаемые репрезентации слов, учитываяследующее ограничение: слова, которые по мнению носителейязыка похожи по значению, должны обладать математическисхожими репрезентациями.
«Светильник» должен быть похож на «лампу», но не на«кипятильник», хотя судя по их поверхностной форме, должнобыть наоборот.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 7
/ 43

Зачем семантическая близость?
Как представить значение слова?
Семантика успешно сопротивляется попыткам формальногопредставления.
Чтобы понять, какие слова семантически близки, необходимопридумать машиночитаемые репрезентации слов, учитываяследующее ограничение: слова, которые по мнению носителейязыка похожи по значению, должны обладать математическисхожими репрезентациями.
«Светильник» должен быть похож на «лампу», но не на«кипятильник», хотя судя по их поверхностной форме, должнобыть наоборот.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 7
/ 43

Зачем семантическая близость?
Как представить значение слова?
Семантика успешно сопротивляется попыткам формальногопредставления.
Чтобы понять, какие слова семантически близки, необходимопридумать машиночитаемые репрезентации слов, учитываяследующее ограничение: слова, которые по мнению носителейязыка похожи по значению, должны обладать математическисхожими репрезентациями.
«Светильник» должен быть похож на «лампу», но не на«кипятильник», хотя судя по их поверхностной форме, должнобыть наоборот.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 7
/ 43

Зачем семантическая близость?
Как представить значение слова?
Семантика успешно сопротивляется попыткам формальногопредставления.
Чтобы понять, какие слова семантически близки, необходимопридумать машиночитаемые репрезентации слов, учитываяследующее ограничение: слова, которые по мнению носителейязыка похожи по значению, должны обладать математическисхожими репрезентациями.
«Светильник» должен быть похож на «лампу», но не на«кипятильник», хотя судя по их поверхностной форме, должнобыть наоборот.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 7
/ 43

Зачем семантическая близость?
Возможные источники данных
Методы автоматического определения семантической близостираспадаются на две большие группы:
Построение онтологий. Knowledge-based подход “сверху вниз”;
Извлечение семантики из повторяющихся паттернов в текстовыхкорпусах. Дистрибутивный подход “снизу вверх”.
Мы говорим о втором подходе: смысл любого данного словаопределяется контекстами, в которых это слово встречается.Иными словами, семантика извлекается из совместной встречаемостислов в большом обучающем корпусе. Это так называемые “счётныедистрибутивно-семантические модели” (count-based distributionalsemantics models).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 8
/ 43

Зачем семантическая близость?
Возможные источники данных
Методы автоматического определения семантической близостираспадаются на две большие группы:
Построение онтологий. Knowledge-based подход “сверху вниз”;
Извлечение семантики из повторяющихся паттернов в текстовыхкорпусах. Дистрибутивный подход “снизу вверх”.
Мы говорим о втором подходе: смысл любого данного словаопределяется контекстами, в которых это слово встречается.Иными словами, семантика извлекается из совместной встречаемостислов в большом обучающем корпусе. Это так называемые “счётныедистрибутивно-семантические модели” (count-based distributionalsemantics models).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 8
/ 43

Зачем семантическая близость?
Возможные источники данных
Методы автоматического определения семантической близостираспадаются на две большие группы:
Построение онтологий. Knowledge-based подход “сверху вниз”;
Извлечение семантики из повторяющихся паттернов в текстовыхкорпусах. Дистрибутивный подход “снизу вверх”.
Мы говорим о втором подходе: смысл любого данного словаопределяется контекстами, в которых это слово встречается.Иными словами, семантика извлекается из совместной встречаемостислов в большом обучающем корпусе. Это так называемые “счётныедистрибутивно-семантические модели” (count-based distributionalsemantics models).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 8
/ 43

Зачем семантическая близость?
Возможные источники данных
Методы автоматического определения семантической близостираспадаются на две большие группы:
Построение онтологий. Knowledge-based подход “сверху вниз”;
Извлечение семантики из повторяющихся паттернов в текстовыхкорпусах. Дистрибутивный подход “снизу вверх”.
Мы говорим о втором подходе: смысл любого данного словаопределяется контекстами, в которых это слово встречается.Иными словами, семантика извлекается из совместной встречаемостислов в большом обучающем корпусе. Это так называемые “счётныедистрибутивно-семантические модели” (count-based distributionalsemantics models).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 8
/ 43

Зачем семантическая близость?
Возможные источники данных
Методы автоматического определения семантической близостираспадаются на две большие группы:
Построение онтологий. Knowledge-based подход “сверху вниз”;
Извлечение семантики из повторяющихся паттернов в текстовыхкорпусах. Дистрибутивный подход “снизу вверх”.
Мы говорим о втором подходе: смысл любого данного словаопределяется контекстами, в которых это слово встречается.
Иными словами, семантика извлекается из совместной встречаемостислов в большом обучающем корпусе. Это так называемые “счётныедистрибутивно-семантические модели” (count-based distributionalsemantics models).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 8
/ 43

Зачем семантическая близость?
Возможные источники данных
Методы автоматического определения семантической близостираспадаются на две большие группы:
Построение онтологий. Knowledge-based подход “сверху вниз”;
Извлечение семантики из повторяющихся паттернов в текстовыхкорпусах. Дистрибутивный подход “снизу вверх”.
Мы говорим о втором подходе: смысл любого данного словаопределяется контекстами, в которых это слово встречается.Иными словами, семантика извлекается из совместной встречаемостислов в большом обучающем корпусе. Это так называемые “счётныедистрибутивно-семантические модели” (count-based distributionalsemantics models).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 8
/ 43

Зачем семантическая близость?
Семантически близкие слова близки друг другу в пространстве ихтипичных соседей
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 9
/ 43

План
1 Зачем семантическая близость?
2 Настало время нейронных моделей
3 Описание соревнования
4 Использованные корпуса
5 Оценка качества
6 Крутим ручки: важность гиперпараметров
7 Русский национальный корпус неожиданно выигрывает
8 Что ещё можно делать с дистрибутивно-семантическими моделями
9 Узнать больше
10 Вопросы
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 10
/ 43

Настало время нейронных моделей
Искуственные нейронные сети позволили дистрибутивнойсемантике перейти к так называемым “предсказательныммоделям” (predict models).
В счетных моделях мы считаем частоту соседства слов с другимисловами и работаем с вектором таких частот (очень высокойразмерности).
В предсказательных моделях мы используем машинное обучение(в частности, нейронные сети) и напрямую выучиваем вектора,которые максимизируют схожесть между контекстными соседями,которых мы наблюдаем в данных, и минимизируют схожесть дляконтекстов, которые в данных (то есть. в корпусе) не встречались.
На выходе мы получаем neural embeddings: сжатые вектора низкойразмерности (порядка нескольких сотен компонентов).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 11
/ 43

Настало время нейронных моделей
Искуственные нейронные сети позволили дистрибутивнойсемантике перейти к так называемым “предсказательныммоделям” (predict models).
В счетных моделях мы считаем частоту соседства слов с другимисловами и работаем с вектором таких частот (очень высокойразмерности).
В предсказательных моделях мы используем машинное обучение(в частности, нейронные сети) и напрямую выучиваем вектора,которые максимизируют схожесть между контекстными соседями,которых мы наблюдаем в данных, и минимизируют схожесть дляконтекстов, которые в данных (то есть. в корпусе) не встречались.
На выходе мы получаем neural embeddings: сжатые вектора низкойразмерности (порядка нескольких сотен компонентов).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 11
/ 43

Настало время нейронных моделей
Искуственные нейронные сети позволили дистрибутивнойсемантике перейти к так называемым “предсказательныммоделям” (predict models).
В счетных моделях мы считаем частоту соседства слов с другимисловами и работаем с вектором таких частот (очень высокойразмерности).
В предсказательных моделях мы используем машинное обучение(в частности, нейронные сети) и напрямую выучиваем вектора,которые максимизируют схожесть между контекстными соседями,которых мы наблюдаем в данных, и минимизируют схожесть дляконтекстов, которые в данных (то есть. в корпусе) не встречались.
На выходе мы получаем neural embeddings: сжатые вектора низкойразмерности (порядка нескольких сотен компонентов).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 11
/ 43

Настало время нейронных моделей
Искуственные нейронные сети позволили дистрибутивнойсемантике перейти к так называемым “предсказательныммоделям” (predict models).
В счетных моделях мы считаем частоту соседства слов с другимисловами и работаем с вектором таких частот (очень высокойразмерности).
В предсказательных моделях мы используем машинное обучение(в частности, нейронные сети) и напрямую выучиваем вектора,которые максимизируют схожесть между контекстными соседями,которых мы наблюдаем в данных, и минимизируют схожесть дляконтекстов, которые в данных (то есть. в корпусе) не встречались.
На выходе мы получаем neural embeddings: сжатые вектора низкойразмерности (порядка нескольких сотен компонентов).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 11
/ 43
Настало время нейронных моделей
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 12
/ 43

Настало время нейронных моделей
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 13
/ 43

Настало время нейронных моделей
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 14
/ 43

Настало время нейронных моделей
По мнению некоторых нейролингвистов, когнитивная информация(слова и образы) в мозге хранится в виде паттернов возбужденийнейронов. Очень похоже на векторные репрезентации: значение - этомассив некоторых распределенных «семантических компонентов»,которые могут быть более или менее активированы.
При этом каждый компонент (нейрон) отвечает сразу за несколькоконцептов, и каждый концепт представлен сразу несколькимиактивированными нейронами.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 15
/ 43
Настало время нейронных моделей
По мнению некоторых нейролингвистов, когнитивная информация(слова и образы) в мозге хранится в виде паттернов возбужденийнейронов. Очень похоже на векторные репрезентации: значение - этомассив некоторых распределенных «семантических компонентов»,которые могут быть более или менее активированы.
При этом каждый компонент (нейрон) отвечает сразу за несколькоконцептов, и каждый концепт представлен сразу несколькимиактивированными нейронами.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 15
/ 43

Настало время нейронных моделей
Важно: в предсказательных моделях конкретные компоненты векторов(например, w5) никак не связаны с конкретными словами, как всчётных моделях. Это некие обобщённые «свойства семантическогопространства».
Сначала это кажется парадоксальным.Но, если подумать: наша цель – это создать такие репрезентации дляслов, которые потом можно будет использовать в практическихприложениях. Неважно, что «значат» конкретные компоненты, важно,что в целом модель хорошо представляет семантическое пространствоязыка.Если мы можем посмотреть на репрезентацию слова и сказать, какиеслова к нему близки по смыслу – цель достигнута.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 16
/ 43

Настало время нейронных моделей
Важно: в предсказательных моделях конкретные компоненты векторов(например, w5) никак не связаны с конкретными словами, как всчётных моделях. Это некие обобщённые «свойства семантическогопространства».Сначала это кажется парадоксальным.
Но, если подумать: наша цель – это создать такие репрезентации дляслов, которые потом можно будет использовать в практическихприложениях. Неважно, что «значат» конкретные компоненты, важно,что в целом модель хорошо представляет семантическое пространствоязыка.Если мы можем посмотреть на репрезентацию слова и сказать, какиеслова к нему близки по смыслу – цель достигнута.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 16
/ 43

Настало время нейронных моделей
Важно: в предсказательных моделях конкретные компоненты векторов(например, w5) никак не связаны с конкретными словами, как всчётных моделях. Это некие обобщённые «свойства семантическогопространства».Сначала это кажется парадоксальным.Но, если подумать: наша цель – это создать такие репрезентации дляслов, которые потом можно будет использовать в практическихприложениях. Неважно, что «значат» конкретные компоненты, важно,что в целом модель хорошо представляет семантическое пространствоязыка.
Если мы можем посмотреть на репрезентацию слова и сказать, какиеслова к нему близки по смыслу – цель достигнута.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 16
/ 43

Настало время нейронных моделей
Важно: в предсказательных моделях конкретные компоненты векторов(например, w5) никак не связаны с конкретными словами, как всчётных моделях. Это некие обобщённые «свойства семантическогопространства».Сначала это кажется парадоксальным.Но, если подумать: наша цель – это создать такие репрезентации дляслов, которые потом можно будет использовать в практическихприложениях. Неважно, что «значат» конкретные компоненты, важно,что в целом модель хорошо представляет семантическое пространствоязыка.Если мы можем посмотреть на репрезентацию слова и сказать, какиеслова к нему близки по смыслу – цель достигнута.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 16
/ 43

Настало время нейронных моделей
Широко известны алгоритмы обучения нейронных языковыхмоделей Continuous Bag-of-words (CBOW) и Continuous Skip-gram(skip-gram), реализованные в утилите word2vec [Mikolov et al.2013]
Marco Baroni и другие умные люди показали, что эти алгоритмыпревосходят традиционные счетные дистрибутивно-семантическиемодели на различных семантических задачах для английскогоязыка.
Так ли это для русского?
Мы обучили подобные модели на русском материале ипротестировали их в рамках соревнования RUSSE.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 17
/ 43

Настало время нейронных моделей
Широко известны алгоритмы обучения нейронных языковыхмоделей Continuous Bag-of-words (CBOW) и Continuous Skip-gram(skip-gram), реализованные в утилите word2vec [Mikolov et al.2013]
Marco Baroni и другие умные люди показали, что эти алгоритмыпревосходят традиционные счетные дистрибутивно-семантическиемодели на различных семантических задачах для английскогоязыка.
Так ли это для русского?
Мы обучили подобные модели на русском материале ипротестировали их в рамках соревнования RUSSE.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 17
/ 43

Настало время нейронных моделей
Широко известны алгоритмы обучения нейронных языковыхмоделей Continuous Bag-of-words (CBOW) и Continuous Skip-gram(skip-gram), реализованные в утилите word2vec [Mikolov et al.2013]
Marco Baroni и другие умные люди показали, что эти алгоритмыпревосходят традиционные счетные дистрибутивно-семантическиемодели на различных семантических задачах для английскогоязыка.
Так ли это для русского?
Мы обучили подобные модели на русском материале ипротестировали их в рамках соревнования RUSSE.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 17
/ 43

Настало время нейронных моделей
Широко известны алгоритмы обучения нейронных языковыхмоделей Continuous Bag-of-words (CBOW) и Continuous Skip-gram(skip-gram), реализованные в утилите word2vec [Mikolov et al.2013]
Marco Baroni и другие умные люди показали, что эти алгоритмыпревосходят традиционные счетные дистрибутивно-семантическиемодели на различных семантических задачах для английскогоязыка.
Так ли это для русского?
Мы обучили подобные модели на русском материале ипротестировали их в рамках соревнования RUSSE.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 17
/ 43

План
1 Зачем семантическая близость?
2 Настало время нейронных моделей
3 Описание соревнования
4 Использованные корпуса
5 Оценка качества
6 Крутим ручки: важность гиперпараметров
7 Русский национальный корпус неожиданно выигрывает
8 Что ещё можно делать с дистрибутивно-семантическими моделями
9 Узнать больше
10 Вопросы
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 18
/ 43

Описание соревнования
RUSSE - это первая попытка провести соревнование поавтоматическому определению семантической близости для русскогоязыка.
Подробно описано в [Panchenko et al 2015] и наhttp://russe.nlpub.ru/.4 трека:
1 hj (human judgment), определение связанности
2 rt (RuThes), определение связанности
3 ae (Russian Associative Thesaurus), определение ассоциаций
4 ae2 (Sociation database), определение ассоциаций
Участникам предоставляется список пар слов; задача в том, чтобывычислить для каждой пары семантическую близость в диапазоне[0;1]. Качество оценивается по степени приближения к “золотомустандарту”: коэффициент Спирмена для hj, и average precision для всехостальных треков.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 19
/ 43

Описание соревнования
RUSSE - это первая попытка провести соревнование поавтоматическому определению семантической близости для русскогоязыка.Подробно описано в [Panchenko et al 2015] и наhttp://russe.nlpub.ru/.
4 трека:
1 hj (human judgment), определение связанности
2 rt (RuThes), определение связанности
3 ae (Russian Associative Thesaurus), определение ассоциаций
4 ae2 (Sociation database), определение ассоциаций
Участникам предоставляется список пар слов; задача в том, чтобывычислить для каждой пары семантическую близость в диапазоне[0;1]. Качество оценивается по степени приближения к “золотомустандарту”: коэффициент Спирмена для hj, и average precision для всехостальных треков.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 19
/ 43

Описание соревнования
RUSSE - это первая попытка провести соревнование поавтоматическому определению семантической близости для русскогоязыка.Подробно описано в [Panchenko et al 2015] и наhttp://russe.nlpub.ru/.4 трека:
1 hj (human judgment), определение связанности
2 rt (RuThes), определение связанности
3 ae (Russian Associative Thesaurus), определение ассоциаций
4 ae2 (Sociation database), определение ассоциаций
Участникам предоставляется список пар слов; задача в том, чтобывычислить для каждой пары семантическую близость в диапазоне[0;1]. Качество оценивается по степени приближения к “золотомустандарту”: коэффициент Спирмена для hj, и average precision для всехостальных треков.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 19
/ 43

Описание соревнования
RUSSE - это первая попытка провести соревнование поавтоматическому определению семантической близости для русскогоязыка.Подробно описано в [Panchenko et al 2015] и наhttp://russe.nlpub.ru/.4 трека:
1 hj (human judgment), определение связанности
2 rt (RuThes), определение связанности
3 ae (Russian Associative Thesaurus), определение ассоциаций
4 ae2 (Sociation database), определение ассоциаций
Участникам предоставляется список пар слов; задача в том, чтобывычислить для каждой пары семантическую близость в диапазоне[0;1]. Качество оценивается по степени приближения к “золотомустандарту”: коэффициент Спирмена для hj, и average precision для всехостальных треков.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 19
/ 43

План
1 Зачем семантическая близость?
2 Настало время нейронных моделей
3 Описание соревнования
4 Использованные корпуса
5 Оценка качества
6 Крутим ручки: важность гиперпараметров
7 Русский национальный корпус неожиданно выигрывает
8 Что ещё можно делать с дистрибутивно-семантическими моделями
9 Узнать больше
10 Вопросы
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 20
/ 43
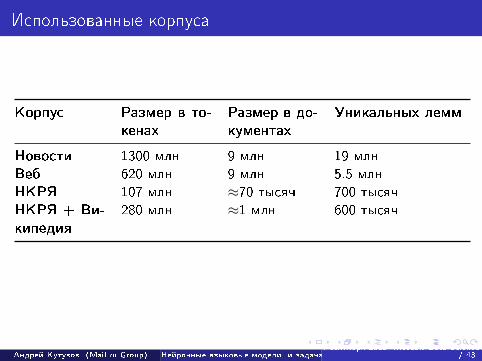
Использованные корпуса
Корпус Размер в то-кенах
Размер в до-кументах
Уникальных лемм
Новости 1300 млн 9 млн 19 млнВеб 620 млн 9 млн 5.5 млнНКРЯ 107 млн ≈70 тысяч 700 тысячНКРЯ + Ви-кипедия
280 млн ≈1 млн 600 тысяч
Все корпусы были лемматизированы при помощи Mystem 3.0 свключенным разрешением неоднозначности. Стоп-слова иоднословные предложения удалялись.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 21
/ 43

Использованные корпуса
Корпус Размер в то-кенах
Размер в до-кументах
Уникальных лемм
Новости 1300 млн 9 млн 19 млнВеб 620 млн 9 млн 5.5 млнНКРЯ 107 млн ≈70 тысяч 700 тысячНКРЯ + Ви-кипедия
280 млн ≈1 млн 600 тысяч
Все корпусы были лемматизированы при помощи Mystem 3.0 свключенным разрешением неоднозначности. Стоп-слова иоднословные предложения удалялись.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 21
/ 43
План
1 Зачем семантическая близость?
2 Настало время нейронных моделей
3 Описание соревнования
4 Использованные корпуса
5 Оценка качества
6 Крутим ручки: важность гиперпараметров
7 Русский национальный корпус неожиданно выигрывает
8 Что ещё можно делать с дистрибутивно-семантическими моделями
9 Узнать больше
10 Вопросы
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 22
/ 43

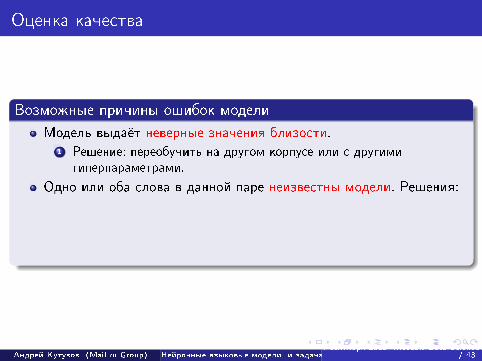
Оценка качества
Возможные причины ошибок модели
Модель выдаёт неверные значения близости.
1 Решение: переобучить на другом корпусе или с другимигиперпараметрами.
Одно или оба слова в данной паре неизвестны модели. Решения:1 Использовать примитивные орфографические меры близости
(”парашют“ - ”парашютист“)2 Сделать запрос к другой модели, обученной на более шумном, но
и более масштабном корпусе (например, НКРЯ и веб-корпус).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 23
/ 43

Оценка качества
Возможные причины ошибок модели
Модель выдаёт неверные значения близости.1 Решение: переобучить на другом корпусе или с другими
гиперпараметрами.
Одно или оба слова в данной паре неизвестны модели. Решения:1 Использовать примитивные орфографические меры близости
(”парашют“ - ”парашютист“)2 Сделать запрос к другой модели, обученной на более шумном, но
и более масштабном корпусе (например, НКРЯ и веб-корпус).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 23
/ 43
Оценка качества
Возможные причины ошибок модели
Модель выдаёт неверные значения близости.1 Решение: переобучить на другом корпусе или с другими
гиперпараметрами.
Одно или оба слова в данной паре неизвестны модели. Решения:
1 Использовать примитивные орфографические меры близости(”парашют“ - ”парашютист“)
2 Сделать запрос к другой модели, обученной на более шумном, нои более масштабном корпусе (например, НКРЯ и веб-корпус).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 23
/ 43

Оценка качества
Возможные причины ошибок модели
Модель выдаёт неверные значения близости.1 Решение: переобучить на другом корпусе или с другими
гиперпараметрами.
Одно или оба слова в данной паре неизвестны модели. Решения:1 Использовать примитивные орфографические меры близости
(”парашют“ - ”парашютист“)
2 Сделать запрос к другой модели, обученной на более шумном, нои более масштабном корпусе (например, НКРЯ и веб-корпус).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 23
/ 43

Оценка качества
Возможные причины ошибок модели
Модель выдаёт неверные значения близости.1 Решение: переобучить на другом корпусе или с другими
гиперпараметрами.
Одно или оба слова в данной паре неизвестны модели. Решения:1 Использовать примитивные орфографические меры близости
(”парашют“ - ”парашютист“)2 Сделать запрос к другой модели, обученной на более шумном, но
и более масштабном корпусе (например, НКРЯ и веб-корпус).
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 23
/ 43

План
1 Зачем семантическая близость?
2 Настало время нейронных моделей
3 Описание соревнования
4 Использованные корпуса
5 Оценка качества
6 Крутим ручки: важность гиперпараметров
7 Русский национальный корпус неожиданно выигрывает
8 Что ещё можно делать с дистрибутивно-семантическими моделями
9 Узнать больше
10 Вопросы
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 24
/ 43

Крутим ручки: важность гиперпараметров
Всё сложно
Качество моделей критически зависит и от гиперпараметров обучения:
1 CBOW или skip-gram алгоритмы. SkipGram лучше показал себядля русского материала, но он медленнее. На небольших корпусах(менее ста миллионов токенов) CBOW начинает выигрывать
2 Размерность векторов: сколько распределённых семантическихсвойств (измерений) мы используем для описания слов.
3 Размер окна: ширина контекста. На широком получаютсятематические (ассоциативные) модели, на узком -функциональные (собственно семантические).
4 Порог частотности:полезно для отсечения низкочастотногодлинного хвоста.
5 Способ отбора целей обучения: иерархический софтмакс илинегативное сэмплирование.
6 Количество итераций над корпусом, и т.д....
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 25
/ 43

Крутим ручки: важность гиперпараметров
Всё сложно
Качество моделей критически зависит и от гиперпараметров обучения:
1 CBOW или skip-gram алгоритмы. SkipGram лучше показал себядля русского материала, но он медленнее. На небольших корпусах(менее ста миллионов токенов) CBOW начинает выигрывать
2 Размерность векторов: сколько распределённых семантическихсвойств (измерений) мы используем для описания слов.
3 Размер окна: ширина контекста. На широком получаютсятематические (ассоциативные) модели, на узком -функциональные (собственно семантические).
4 Порог частотности:полезно для отсечения низкочастотногодлинного хвоста.
5 Способ отбора целей обучения: иерархический софтмакс илинегативное сэмплирование.
6 Количество итераций над корпусом, и т.д....
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 25
/ 43

Крутим ручки: важность гиперпараметров
Всё сложно
Качество моделей критически зависит и от гиперпараметров обучения:
1 CBOW или skip-gram алгоритмы. SkipGram лучше показал себядля русского материала, но он медленнее. На небольших корпусах(менее ста миллионов токенов) CBOW начинает выигрывать
2 Размерность векторов: сколько распределённых семантическихсвойств (измерений) мы используем для описания слов.
3 Размер окна: ширина контекста. На широком получаютсятематические (ассоциативные) модели, на узком -функциональные (собственно семантические).
4 Порог частотности:полезно для отсечения низкочастотногодлинного хвоста.
5 Способ отбора целей обучения: иерархический софтмакс илинегативное сэмплирование.
6 Количество итераций над корпусом, и т.д....
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 25
/ 43

Крутим ручки: важность гиперпараметров
Всё сложно
Качество моделей критически зависит и от гиперпараметров обучения:
1 CBOW или skip-gram алгоритмы. SkipGram лучше показал себядля русского материала, но он медленнее. На небольших корпусах(менее ста миллионов токенов) CBOW начинает выигрывать
2 Размерность векторов: сколько распределённых семантическихсвойств (измерений) мы используем для описания слов.
3 Размер окна: ширина контекста. На широком получаютсятематические (ассоциативные) модели, на узком -функциональные (собственно семантические).
4 Порог частотности:полезно для отсечения низкочастотногодлинного хвоста.
5 Способ отбора целей обучения: иерархический софтмакс илинегативное сэмплирование.
6 Количество итераций над корпусом, и т.д....
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 25
/ 43

Крутим ручки: важность гиперпараметров
Всё сложно
Качество моделей критически зависит и от гиперпараметров обучения:
1 CBOW или skip-gram алгоритмы. SkipGram лучше показал себядля русского материала, но он медленнее. На небольших корпусах(менее ста миллионов токенов) CBOW начинает выигрывать
2 Размерность векторов: сколько распределённых семантическихсвойств (измерений) мы используем для описания слов.
3 Размер окна: ширина контекста. На широком получаютсятематические (ассоциативные) модели, на узком -функциональные (собственно семантические).
4 Порог частотности:полезно для отсечения низкочастотногодлинного хвоста.
5 Способ отбора целей обучения: иерархический софтмакс илинегативное сэмплирование.
6 Количество итераций над корпусом, и т.д....
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 25
/ 43

Крутим ручки: важность гиперпараметров
Всё сложно
Качество моделей критически зависит и от гиперпараметров обучения:
1 CBOW или skip-gram алгоритмы. SkipGram лучше показал себядля русского материала, но он медленнее. На небольших корпусах(менее ста миллионов токенов) CBOW начинает выигрывать
2 Размерность векторов: сколько распределённых семантическихсвойств (измерений) мы используем для описания слов.
3 Размер окна: ширина контекста. На широком получаютсятематические (ассоциативные) модели, на узком -функциональные (собственно семантические).
4 Порог частотности:полезно для отсечения низкочастотногодлинного хвоста.
5 Способ отбора целей обучения: иерархический софтмакс илинегативное сэмплирование.
6 Количество итераций над корпусом, и т.д....Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка
4 сентября 2015 Moscow Data Science Meetup 25/ 43

Крутим ручки: важность гиперпараметров
Универсального рецепта нет:набор оптимальных гиперпараметров следует подбирать для каждойконкретной задачи.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 26
/ 43

Крутим ручки: важность гиперпараметров
Качество модели на НКРЯ в треке rt в зависимости от размеравектора.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 27
/ 43

Крутим ручки: важность гиперпараметров
Качество модели на веб-корпусе в треке rt в зависимости от размеравектора.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 28
/ 43

Крутим ручки: важность гиперпараметров
Качество модели на корпусе новостей в треке rt в зависимости отразмера окна.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 29
/ 43

Крутим ручки: важность гиперпараметров
Качество модели на НКРЯ в треке ae2 в зависимости от размераокна.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 30
/ 43
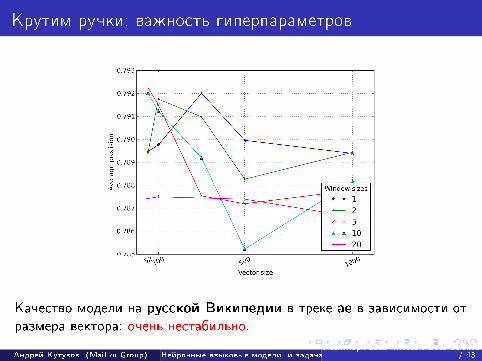
Крутим ручки: важность гиперпараметров
Качество модели на русской Википедии в треке ae в зависимости отразмера вектора: очень нестабильно.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 31
/ 43
Крутим ручки: важность гиперпараметров
Больше данных в сети
http://ling.go.mail.ru/misc/dialogue_2015.html
Диаграммы качества для всех комбинаций гиперпараметров;
Модели, обученные с оптимальными для данной задачинастройками.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 32
/ 43
План
1 Зачем семантическая близость?
2 Настало время нейронных моделей
3 Описание соревнования
4 Использованные корпуса
5 Оценка качества
6 Крутим ручки: важность гиперпараметров
7 Русский национальный корпус неожиданно выигрывает
8 Что ещё можно делать с дистрибутивно-семантическими моделями
9 Узнать больше
10 Вопросы
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 33
/ 43

Русский национальный корпус неожиданно выигрывает
Модели, обученные на НКРЯ, регулярно превосходили своихсоперников, часто даже на векторах меньшей размерности: этоособенно заметно в треках на семантические отношения (вотличие от ассоциативных).Учитывая, что НКРЯ существенно меньше по размеру, это оченьвпечатляет.
Похоже, что корпус действительно репрезентативен по отношениюк русскому языку в целом: сбалансированный лингвистическийматериал для всех слоёв словаря.Очень мало шума и ”грязных“ кусков текста.
...рулит!
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 34
/ 43

Русский национальный корпус неожиданно выигрывает
Модели, обученные на НКРЯ, регулярно превосходили своихсоперников, часто даже на векторах меньшей размерности: этоособенно заметно в треках на семантические отношения (вотличие от ассоциативных).Учитывая, что НКРЯ существенно меньше по размеру, это оченьвпечатляет.Похоже, что корпус действительно репрезентативен по отношениюк русскому языку в целом: сбалансированный лингвистическийматериал для всех слоёв словаря.
Очень мало шума и ”грязных“ кусков текста.
...рулит!
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 34
/ 43

Русский национальный корпус неожиданно выигрывает
Модели, обученные на НКРЯ, регулярно превосходили своихсоперников, часто даже на векторах меньшей размерности: этоособенно заметно в треках на семантические отношения (вотличие от ассоциативных).Учитывая, что НКРЯ существенно меньше по размеру, это оченьвпечатляет.Похоже, что корпус действительно репрезентативен по отношениюк русскому языку в целом: сбалансированный лингвистическийматериал для всех слоёв словаря.Очень мало шума и ”грязных“ кусков текста.
...рулит!
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 34
/ 43

Русский национальный корпус неожиданно выигрывает
Модели, обученные на НКРЯ, регулярно превосходили своихсоперников, часто даже на векторах меньшей размерности: этоособенно заметно в треках на семантические отношения (вотличие от ассоциативных).Учитывая, что НКРЯ существенно меньше по размеру, это оченьвпечатляет.Похоже, что корпус действительно репрезентативен по отношениюк русскому языку в целом: сбалансированный лингвистическийматериал для всех слоёв словаря.Очень мало шума и ”грязных“ кусков текста.
...рулит!
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 34
/ 43

Русский национальный корпус неожиданно выигрывает
Модели, обученные на НКРЯ, регулярно превосходили своихсоперников, часто даже на векторах меньшей размерности: этоособенно заметно в треках на семантические отношения (вотличие от ассоциативных).Учитывая, что НКРЯ существенно меньше по размеру, это оченьвпечатляет.Похоже, что корпус действительно репрезентативен по отношениюк русскому языку в целом: сбалансированный лингвистическийматериал для всех слоёв словаря.Очень мало шума и ”грязных“ кусков текста.
...рулит!
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 34
/ 43

Русский национальный корпус неожиданно выигрывает
Ещё немного наблюдений
Википедия не является хорошим обучающим корпусом.
Полезно добавлять к словам идентификатор части речи(”стать_V“): видимо, помогает модели снимать частеречнуюомонимию.
С CBOW нужно использовать иерархический софтмакс, а соSkipGram - негативное сэмплирование (от 10 сэмплов); еслисделать наоборот, наблюдается резкое падение качества.
Комбинация SkipGram+ns10 в целом чаще выигрывает, и сростом объёма корпуса это всё заметнее.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 35
/ 43

Русский национальный корпус неожиданно выигрывает
Ещё немного наблюдений
Википедия не является хорошим обучающим корпусом.
Полезно добавлять к словам идентификатор части речи(”стать_V“): видимо, помогает модели снимать частеречнуюомонимию.
С CBOW нужно использовать иерархический софтмакс, а соSkipGram - негативное сэмплирование (от 10 сэмплов); еслисделать наоборот, наблюдается резкое падение качества.
Комбинация SkipGram+ns10 в целом чаще выигрывает, и сростом объёма корпуса это всё заметнее.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 35
/ 43

Русский национальный корпус неожиданно выигрывает
Ещё немного наблюдений
Википедия не является хорошим обучающим корпусом.
Полезно добавлять к словам идентификатор части речи(”стать_V“): видимо, помогает модели снимать частеречнуюомонимию.
С CBOW нужно использовать иерархический софтмакс, а соSkipGram - негативное сэмплирование (от 10 сэмплов); еслисделать наоборот, наблюдается резкое падение качества.
Комбинация SkipGram+ns10 в целом чаще выигрывает, и сростом объёма корпуса это всё заметнее.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 35
/ 43

Русский национальный корпус неожиданно выигрывает
Ещё немного наблюдений
Википедия не является хорошим обучающим корпусом.
Полезно добавлять к словам идентификатор части речи(”стать_V“): видимо, помогает модели снимать частеречнуюомонимию.
С CBOW нужно использовать иерархический софтмакс, а соSkipGram - негативное сэмплирование (от 10 сэмплов); еслисделать наоборот, наблюдается резкое падение качества.
Комбинация SkipGram+ns10 в целом чаще выигрывает, и сростом объёма корпуса это всё заметнее.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 35
/ 43

Русский национальный корпус неожиданно выигрывает
И снова про сервис http://ling.go.mail.ru/dsm:
Поиск ближайших семантических соседей русских слов;
Вычисление косинусной близости между парами слов;
Алгебраические операции над лексическими векторами (‘крыло’ -‘самолет’ + ‘машина’ = ‘колесо’);
Ограничение результатов конкретной частью речи;
Используйте наши модели, обученные на разных корпусах;
... или загрузите ваш собственный корпус, и мы обучим модель нанём;
Каждое слово в каждой модели обладает собственнымуникальным URI:
http://ling.go.mail.ru/dsm/ru/ruscorpora/наука ;
Лицензия Creative Commons Attribution;
Регулярно добавляются новые возможности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 36
/ 43

Русский национальный корпус неожиданно выигрывает
И снова про сервис http://ling.go.mail.ru/dsm:
Поиск ближайших семантических соседей русских слов;
Вычисление косинусной близости между парами слов;
Алгебраические операции над лексическими векторами (‘крыло’ -‘самолет’ + ‘машина’ = ‘колесо’);
Ограничение результатов конкретной частью речи;
Используйте наши модели, обученные на разных корпусах;
... или загрузите ваш собственный корпус, и мы обучим модель нанём;
Каждое слово в каждой модели обладает собственнымуникальным URI:
http://ling.go.mail.ru/dsm/ru/ruscorpora/наука ;
Лицензия Creative Commons Attribution;
Регулярно добавляются новые возможности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 36
/ 43

Русский национальный корпус неожиданно выигрывает
И снова про сервис http://ling.go.mail.ru/dsm:
Поиск ближайших семантических соседей русских слов;
Вычисление косинусной близости между парами слов;
Алгебраические операции над лексическими векторами (‘крыло’ -‘самолет’ + ‘машина’ = ‘колесо’);
Ограничение результатов конкретной частью речи;
Используйте наши модели, обученные на разных корпусах;
... или загрузите ваш собственный корпус, и мы обучим модель нанём;
Каждое слово в каждой модели обладает собственнымуникальным URI:
http://ling.go.mail.ru/dsm/ru/ruscorpora/наука ;
Лицензия Creative Commons Attribution;
Регулярно добавляются новые возможности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 36
/ 43

Русский национальный корпус неожиданно выигрывает
И снова про сервис http://ling.go.mail.ru/dsm:
Поиск ближайших семантических соседей русских слов;
Вычисление косинусной близости между парами слов;
Алгебраические операции над лексическими векторами (‘крыло’ -‘самолет’ + ‘машина’ = ‘колесо’);
Ограничение результатов конкретной частью речи;
Используйте наши модели, обученные на разных корпусах;
... или загрузите ваш собственный корпус, и мы обучим модель нанём;
Каждое слово в каждой модели обладает собственнымуникальным URI:
http://ling.go.mail.ru/dsm/ru/ruscorpora/наука ;
Лицензия Creative Commons Attribution;
Регулярно добавляются новые возможности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 36
/ 43

Русский национальный корпус неожиданно выигрывает
И снова про сервис http://ling.go.mail.ru/dsm:
Поиск ближайших семантических соседей русских слов;
Вычисление косинусной близости между парами слов;
Алгебраические операции над лексическими векторами (‘крыло’ -‘самолет’ + ‘машина’ = ‘колесо’);
Ограничение результатов конкретной частью речи;
Используйте наши модели, обученные на разных корпусах;
... или загрузите ваш собственный корпус, и мы обучим модель нанём;
Каждое слово в каждой модели обладает собственнымуникальным URI:
http://ling.go.mail.ru/dsm/ru/ruscorpora/наука ;
Лицензия Creative Commons Attribution;
Регулярно добавляются новые возможности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 36
/ 43

Русский национальный корпус неожиданно выигрывает
И снова про сервис http://ling.go.mail.ru/dsm:
Поиск ближайших семантических соседей русских слов;
Вычисление косинусной близости между парами слов;
Алгебраические операции над лексическими векторами (‘крыло’ -‘самолет’ + ‘машина’ = ‘колесо’);
Ограничение результатов конкретной частью речи;
Используйте наши модели, обученные на разных корпусах;
... или загрузите ваш собственный корпус, и мы обучим модель нанём;
Каждое слово в каждой модели обладает собственнымуникальным URI:
http://ling.go.mail.ru/dsm/ru/ruscorpora/наука ;
Лицензия Creative Commons Attribution;
Регулярно добавляются новые возможности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 36
/ 43

Русский национальный корпус неожиданно выигрывает
И снова про сервис http://ling.go.mail.ru/dsm:
Поиск ближайших семантических соседей русских слов;
Вычисление косинусной близости между парами слов;
Алгебраические операции над лексическими векторами (‘крыло’ -‘самолет’ + ‘машина’ = ‘колесо’);
Ограничение результатов конкретной частью речи;
Используйте наши модели, обученные на разных корпусах;
... или загрузите ваш собственный корпус, и мы обучим модель нанём;
Каждое слово в каждой модели обладает собственнымуникальным URI:
http://ling.go.mail.ru/dsm/ru/ruscorpora/наука ;
Лицензия Creative Commons Attribution;
Регулярно добавляются новые возможности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 36
/ 43

Русский национальный корпус неожиданно выигрывает
И снова про сервис http://ling.go.mail.ru/dsm:
Поиск ближайших семантических соседей русских слов;
Вычисление косинусной близости между парами слов;
Алгебраические операции над лексическими векторами (‘крыло’ -‘самолет’ + ‘машина’ = ‘колесо’);
Ограничение результатов конкретной частью речи;
Используйте наши модели, обученные на разных корпусах;
... или загрузите ваш собственный корпус, и мы обучим модель нанём;
Каждое слово в каждой модели обладает собственнымуникальным URI:
http://ling.go.mail.ru/dsm/ru/ruscorpora/наука ;
Лицензия Creative Commons Attribution;
Регулярно добавляются новые возможности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 36
/ 43

Русский национальный корпус неожиданно выигрывает
И снова про сервис http://ling.go.mail.ru/dsm:
Поиск ближайших семантических соседей русских слов;
Вычисление косинусной близости между парами слов;
Алгебраические операции над лексическими векторами (‘крыло’ -‘самолет’ + ‘машина’ = ‘колесо’);
Ограничение результатов конкретной частью речи;
Используйте наши модели, обученные на разных корпусах;
... или загрузите ваш собственный корпус, и мы обучим модель нанём;
Каждое слово в каждой модели обладает собственнымуникальным URI:
http://ling.go.mail.ru/dsm/ru/ruscorpora/наука ;
Лицензия Creative Commons Attribution;
Регулярно добавляются новые возможности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 36
/ 43

План
1 Зачем семантическая близость?
2 Настало время нейронных моделей
3 Описание соревнования
4 Использованные корпуса
5 Оценка качества
6 Крутим ручки: важность гиперпараметров
7 Русский национальный корпус неожиданно выигрывает
8 Что ещё можно делать с дистрибутивно-семантическими моделями
9 Узнать больше
10 Вопросы
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 37
/ 43

Что ещё можно делать с дистрибутивно-семантическими
моделями
Необходимо тщательное сравнение различий между моделями,обученными с разными гиперпараметрами
Кластеризация векторных репрезентаций слов позволяетвыделить общие семантические классы (кроме прочего, полезно вопределении именованных сущностей (NER), см. [Siencnik 2015]);
Полученные сжатые вектора можно использовать в типичныхзадачах поисковых движков: расширение запросов,”семантическое хэширование“ документов и т.д.
Рекомендательные системы;
Анализ тональности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 38
/ 43

Что ещё можно делать с дистрибутивно-семантическими
моделями
Необходимо тщательное сравнение различий между моделями,обученными с разными гиперпараметрами
Кластеризация векторных репрезентаций слов позволяетвыделить общие семантические классы (кроме прочего, полезно вопределении именованных сущностей (NER), см. [Siencnik 2015]);
Полученные сжатые вектора можно использовать в типичныхзадачах поисковых движков: расширение запросов,”семантическое хэширование“ документов и т.д.
Рекомендательные системы;
Анализ тональности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 38
/ 43

Что ещё можно делать с дистрибутивно-семантическими
моделями
Необходимо тщательное сравнение различий между моделями,обученными с разными гиперпараметрами
Кластеризация векторных репрезентаций слов позволяетвыделить общие семантические классы (кроме прочего, полезно вопределении именованных сущностей (NER), см. [Siencnik 2015]);
Полученные сжатые вектора можно использовать в типичныхзадачах поисковых движков: расширение запросов,”семантическое хэширование“ документов и т.д.
Рекомендательные системы;
Анализ тональности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 38
/ 43

Что ещё можно делать с дистрибутивно-семантическими
моделями
Необходимо тщательное сравнение различий между моделями,обученными с разными гиперпараметрами
Кластеризация векторных репрезентаций слов позволяетвыделить общие семантические классы (кроме прочего, полезно вопределении именованных сущностей (NER), см. [Siencnik 2015]);
Полученные сжатые вектора можно использовать в типичныхзадачах поисковых движков: расширение запросов,”семантическое хэширование“ документов и т.д.
Рекомендательные системы;
Анализ тональности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 38
/ 43

Что ещё можно делать с дистрибутивно-семантическими
моделями
Необходимо тщательное сравнение различий между моделями,обученными с разными гиперпараметрами
Кластеризация векторных репрезентаций слов позволяетвыделить общие семантические классы (кроме прочего, полезно вопределении именованных сущностей (NER), см. [Siencnik 2015]);
Полученные сжатые вектора можно использовать в типичныхзадачах поисковых движков: расширение запросов,”семантическое хэширование“ документов и т.д.
Рекомендательные системы;
Анализ тональности.
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 38
/ 43

План
1 Зачем семантическая близость?
2 Настало время нейронных моделей
3 Описание соревнования
4 Использованные корпуса
5 Оценка качества
6 Крутим ручки: важность гиперпараметров
7 Русский национальный корпус неожиданно выигрывает
8 Что ещё можно делать с дистрибутивно-семантическими моделями
9 Узнать больше
10 Вопросы
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 39
/ 43

Узнать больше
Почитать:
1 Mikolov, Tomas, et al. "Efficient estimation of word representations invector space." arXiv preprint arXiv:1301.3781 (2013).
2 Baroni, Marco, Georgiana Dinu, and German Kruszewski. "Don’tcount, predict! a systematic comparison of context-counting vs.context-predicting semantic vectors." Proceedings of the 52nd AnnualMeeting of the Association for Computational Linguistics. Vol. 1. 2014.
3 Levy, Omer, and Yoav Goldberg. "Dependency-based wordembeddings." Proceedings of the 52nd Annual Meeting of theAssociation for Computational Linguistics. Vol. 2. 2014.
4 Kutuzov, Andrey and Andreev, Igor. “Texts in, meaning out: neurallanguage models in semantic similarity task for Russian.” Proceedingsof the Dialog 2015 Conference, Moscow, Russia
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 40
/ 43

Узнать больше
Поработать:
1 https://code.google.com/p/word2vec/
2 http://radimrehurek.com/2014/02/word2vec-tutorial/
3 http://ling.go.mail.ru/dsm
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 41
/ 43

План
1 Зачем семантическая близость?
2 Настало время нейронных моделей
3 Описание соревнования
4 Использованные корпуса
5 Оценка качества
6 Крутим ручки: важность гиперпараметров
7 Русский национальный корпус неожиданно выигрывает
8 Что ещё можно делать с дистрибутивно-семантическими моделями
9 Узнать больше
10 Вопросы
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 42
/ 43

Вопросы
Спасибо!
Вопросы?
Нейронные языковые модели и задача определения семантическойблизости слов для русского языка
Андрей Кутузов ([email protected])
4 сентября 2015Moscow Data Science Meetup
Андрей Кутузов (Mail.ru Group) Нейронные языковые модели и задача определения семантической близости слов для русского языка4 сентября 2015 Moscow Data Science Meetup 43
/ 43


















