![Http://cs273a.stanford.edu [Bejerano Spr06/07] 1 TTh 11:00-12:15 in Clark S361 Profs: Serafim Batzoglou, Gill Bejerano TAs: George Asimenos, Cory McLean.](https://static.fdocuments.us/doc/165x107/56649d605503460f94a412e0/httpcs273astanfordedu-bejerano-spr0607-1-tth-1100-1215-in-clark-s361.jpg)
. A Simple Hyper Geometric Approach for Discovering Putative Transcription Factor Binding Sites...
24
. A Simple Hyper Geometric Approach for Discovering Putative Transcription Factor Binding Sites Yoseph Barash Gill Bejerano Nir Friedman Hebrew University Jerusalem
-
Upload
william-hubbard -
Category
Documents
-
view
217 -
download
2
Transcript of . A Simple Hyper Geometric Approach for Discovering Putative Transcription Factor Binding Sites...

.
A Simple Hyper Geometric Approach for Discovering
Putative Transcription Factor Binding Sites
Yoseph Barash Gill Bejerano Nir Friedman
Hebrew University Jerusalem

Transcription Factors Rule
• Enhance/repress/initiate mRNA expression
*Essential Cell Biology; p.268

The “Biological Hypothesis”
Co-Expression
Experiments
Gen
es
Co-Regulation
Binding Sites within Promoters
Gen
es
Input: a set of upstream regions
Output: common & unique binding sites (putative)

Our Approach: HighlightsDiverse Literature:Bailey & Elkan, 94; Buhler & Tompa, 01; Bussemaker et al, 00; Lawrence et al, 93; Pevzner & Sze, 00; Tavazoie et al, 99;van Helden et al, 00; Vilo et al, 00, …
Our Approach: Expressive binding site model
Systematic exploration of search space
Statistical significance evaluation
Integrate biological knowledge
Computationally efficient

=1=2
ball B(l,)
Basic Motifs
Subsequence
ACT
AAT
GCT
ACCCCT AGT
ACA
ATA
ATC
AGA
TGT
TATTCT
TTT
ATT
AAA
ATT
CCT
ACA
ACT
TCTGCT
ACC
ACG
AGTAAT
ATT
CATCTT
CGT
GGT
GTT
GAT
TGTTTTTAT
CCA
CCC
CCG
l=3

Motif Generalizations Richer alphabets
SCTNNNGTAAR
WATNNNGTCAR
General distance function
Random projections (following [Buhler & Tompa, 01])
l –mers projections using k < l positions
SCTATGAGTAR
SCAATGATCARSC*A*GA**AR

Statistical Significance
We found a motif… is it significant? When using a large space of motifs, we expect some
artifacts
Two types of null-hypothesis Generative
Probability of generating a set of promoters containing this motif
Discriminative
Probability of selecting a set of genes that contain this motif?

Selected genes
Discriminative P-value
Start with the promoter regions of all genes
Mark genes that contain the motif
P-value: Probability of selecting as
many marked genes if we select n genes at random
Promotersequences

Selected genes
Discriminative P-value
Start with the promoter regions of all genes
Mark genes that contain the motif
P-value: Probability of selecting as
many marked genes if we select n genes at random
Promotersequences
n
kxn
M
xn
KM
x
K
MKnkPhyper ),,|(

Statistical Significance Evaluation• What if we select n genes V times?
False Discovery Rate (FDR) (Benjamini & Huchberg,95):
The expected ratio of false motifs identified from the
whole set of motifs identified is no more than
Bonferroni p-value limit (union bound)
for a false positive rate :
Motif is significant if p-value(Motif)
V

FDR Example
3}501.0
|{ Here k
PPArgMax kk
P-value index
prob
abili
ty

Algorithm Outline
Define Space of Motifsalphabet,distance function,motif sets
Evaluate All Motifs using hyper-geometric null model
Choose Significant Motifsusing Bonfferoni or FDR criteria

From Discrete Motif to PSSMPosition Specific Score Matrix:
for a motif of length L define
Pi(A,C,G,T) for i={1….S} where S >= L
1 2 3 4 5
A 0.1 0.25 0.05 0.7 0.6
C 0.3 0.25 0.8 0.1 0.05
G 0.5 0.25 0.05 0.1 0.05
T 0.1 0.25 0.1 0.1 0.22 Aims:
•Refine motif
•Extend seed to flanking regions

Learning a PSSM
Initialize: Find all subsequences of length S that contain the
motif Align them & compute probabilities
Iterative EM - like procedure: Score each position in each gene using the PSSM Use the score to refine the PSSM representation Iterate Remove non informative flanking regions

Algorithm Outline (revisited)
Define Space of Motifsalphabet,distance function,motif sets
Evaluate All Motifs using hyper-geometric null model
Choose Significant Motifsusing Bonfferoni or FDR criteria
Refine motifs into PSSMiterative EM-like procedure

Yeast Results
Major differences: Background discrimination Running time (~1 hour Vs. ~1 Week)
Cluster TF Cons. Seed PSSM MEME < 8Rank p-value Rank p-value Rank E-value
Spellman et al.CLN2* MBF ACGCGT 1 4e-26 1 3e-42 1 1e-18
SIC1 SWI5p CCAGCA 1 1e-12 1 1e-12 1 8e-00
Tavazoie et al.3 Putative GATGAG 5 9e-07 5 6e-09 4 1e+06
Putative GAAAAatT 2 4e-07 2 1e-11 23 8e+07
8 STRE aAGGgG 3 6e-07 3 4e-06 20 1e+08
30 MET31 gCCACAgT 1 2e-11 1 2e-11 2 5e+02
Iyer et al.MBF MBF ACGCGT 1 1e-12 1 3e-18 3 1e+04
SBF** SBF CGCGAAA 1 1e-32 1 1e-37 2 1e-17

Sample Yeast PSSM’s
SBF
CLN2

Human Results* - TGF
BSMC NHBE NHLF
PBS TGF PBS TGF PBS TGF
* Research Collaboration with Naftali Kaminski, Sheba Medical Center Jane Lee, Dean Shappard, UCSF Tommy Kaplan, Hebrew University
Measuring response to TGF in three distinct cell-types in lungs
Each cell type/conditionrepeated at least 4 times
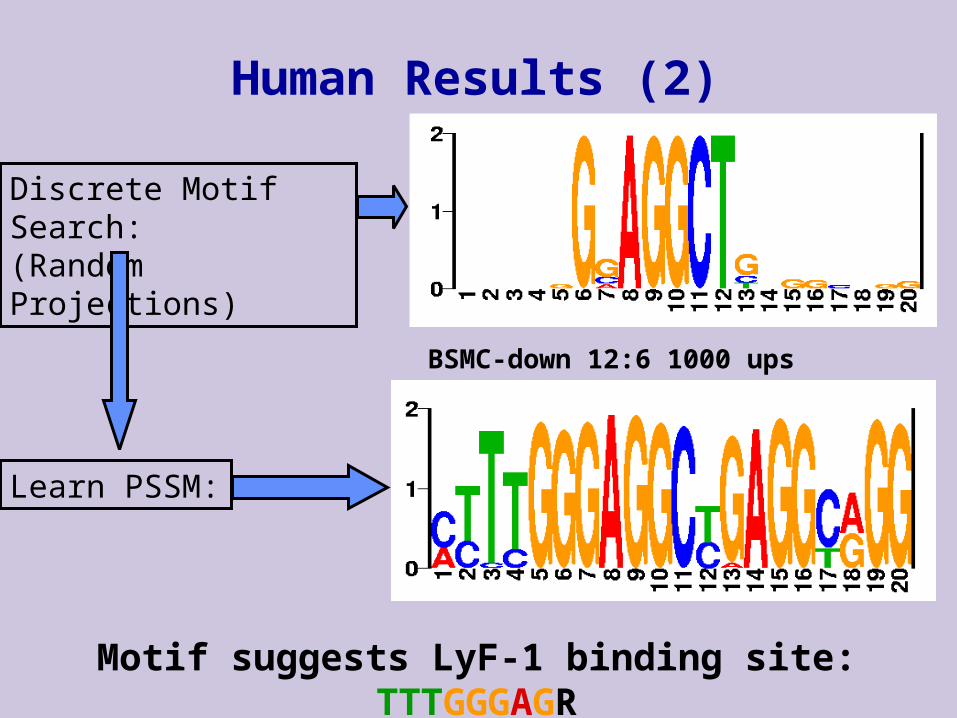
Human Results (2)
BSMC-down 12:6 1000 ups
Discrete Motif Search:(Random Projections)
Learn PSSM:
Motif suggests LyF-1 binding site: TTTGGGAGR

Summary
Efficiency & Modularity Systematic coverage of event space Extension of initial seeds to PSSM Good background discrimination Enables usage of biological prior knowledge Promising preliminary results on biological data sets Fast evaluation tool for possible co-regulated genes

* = 18.3)10,5,5|4( NKnxPvalhyper
G1 19.5 *
G7 19.1
G5 19.1 *
G1 18.5 *
G4 18.3 *
G2 17.2
G9 16.8
G3 15.2
G8 15.1 *
G10 14.8
Updating - Example
Score

Statistical Significance?
Two Basic Approaches for Background modeling:
• Random Generation
• Random Selection
We found a cluster of n genes, x of them contain a motif. Genome has M genes, K of them contain the
motif. How significant is this ?
Same thing as choosing n balls (x of them red),from a set of M balls, with K red ones.

Simple Example
ACGTGTATTAAGTGACTCCTGATTGAG
ACGAGTGACTTGCATATCCTGATTGAG
ACGTGTATTAGATGAAAATTATCCCCC
ACGTGTATTAAATTTCCGGTGTAGTAGAGTGTATTAAACCCCTCTAGTGTTGAG
Here: n = 5, x = 4, M = 100, K = 10
410*51.2)100,10,5|4(
n
M
xn
KM
x
K
MKnxPhyper
5
4'
),,|'()10,100,5,4(#-
x
MKnxPKMnmotifvaluep hyper

Statistical Significance Evaluation• What if we select n genes V times?
Bonferroni p-value limit (union bound)
for a false positive rate :
Motif is significant if p-value(Motif)
False Discovery Rate (FDR) (Benjamini & Huchberg,95):
The expected ratio of false motifs identified from the
whole set of motifs identified is no more than
V
















![Http://cs273a.stanford.edu [Bejerano Aut08/09]1 MW 11:00-12:15 in Beckman B302 Profs: Serafim Batzoglou, Gill Bejerano TAs: Cory McLean, Aaron Wenger.](https://static.fdocuments.us/doc/165x107/56649d555503460f94a328be/httpcs273astanfordedu-bejerano-aut08091-mw-1100-1215-in-beckman-b302.jpg)
![Http://cs273a.stanford.edu [Bejerano Fall09/10] 1 MW 11:00-12:15 in Beckman B302 Profs: Serafim Batzoglou, Gill Bejerano TAs: Aaron Wenger & Gus Katsiapis.](https://static.fdocuments.us/doc/165x107/56649d5c5503460f94a3b1ce/httpcs273astanfordedu-bejerano-fall0910-1-mw-1100-1215-in-beckman.jpg)
