
© 2007 Jimeng Sun Less is More: Compact Matrix Decomposition for Large Sparse Graphs Jimeng Sun,...
47
© 2007 Jimeng Sun Less is More: Compact Matrix Decomposition for Large Sparse Graphs Jimeng Sun, Yinglian Xie, Hui Zhang, Christos Faloutsos Speaker: Jimeng Sun
-
date post
21-Dec-2015 -
Category
Documents
-
view
215 -
download
0
Transcript of © 2007 Jimeng Sun Less is More: Compact Matrix Decomposition for Large Sparse Graphs Jimeng Sun,...

© 2007 Jimeng Sun
Less is More: Compact Matrix Decomposition for Large Sparse
Graphs
Jimeng Sun, Yinglian Xie, Hui Zhang, Christos Faloutsos
Speaker: Jimeng Sun

© 2007 Jimeng Sun2
Motivation
• Sparse matrices are everywhere
Network Forensics
Social network analysis
Web graph analysis
Text mining
# of nonzeros in Amxn= O(m+n)

© 2007 Jimeng Sun3
Motivation
• Sparse matrices are everywhere
Network Forensics
Social network analysis
Web graph analysis
Text mining
How to summarize sparse matrices in a concise and intuitive manner?
Compression, Anomaly detection

© 2007 Jimeng Sun4
Problem: Network forensics
• Input: Network flows <src, dst, # of packets> over time.
<128.2.175.2, 128.2.175.184, 128>
<128.2.1.2, 128.2.175.184, 128>
<128.2.17.43, 128.2.12.1, 128>
…
• Output: Useful patterns
Summarize the traffic flows
Identify abnormal traffic patterns
time
© 2007 Jimeng Sun5
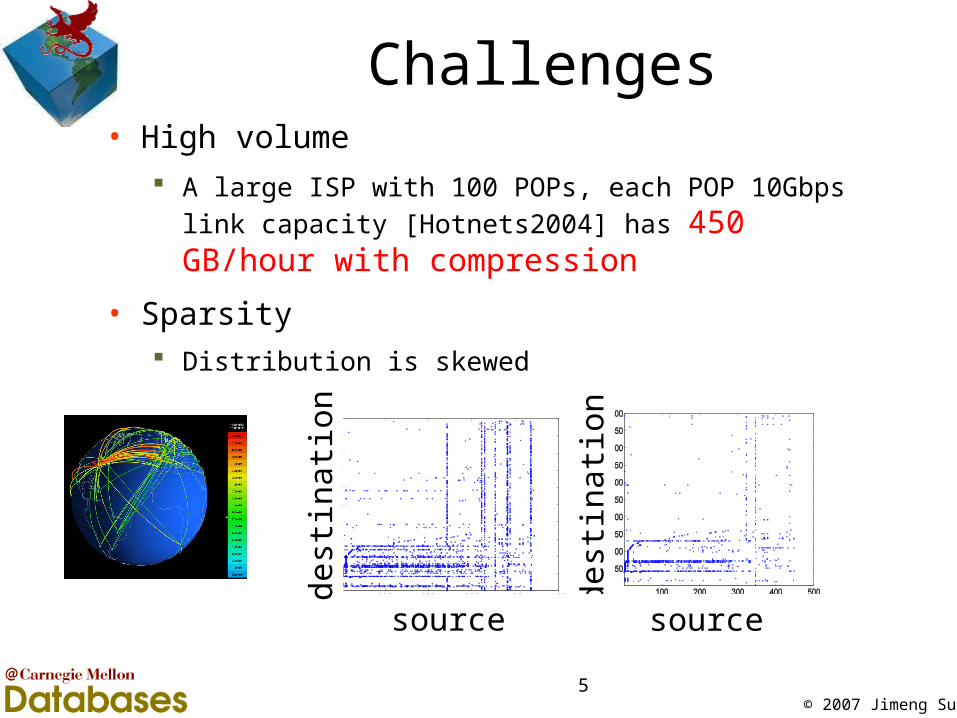
Challenges• High volume
A large ISP with 100 POPs, each POP 10Gbps link capacity
[Hotnets2004] has 450 GB/hour with compression
• Sparsity Distribution is skewed
dest
inati
on
source
dest
inati
on
source

© 2007 Jimeng Sun6
Outline• Motivation
• Problem definition
• Proposed mining framework Sparsification
Matrix decomposition
Error Measure
• Experiments
• Related work
• Conclusion
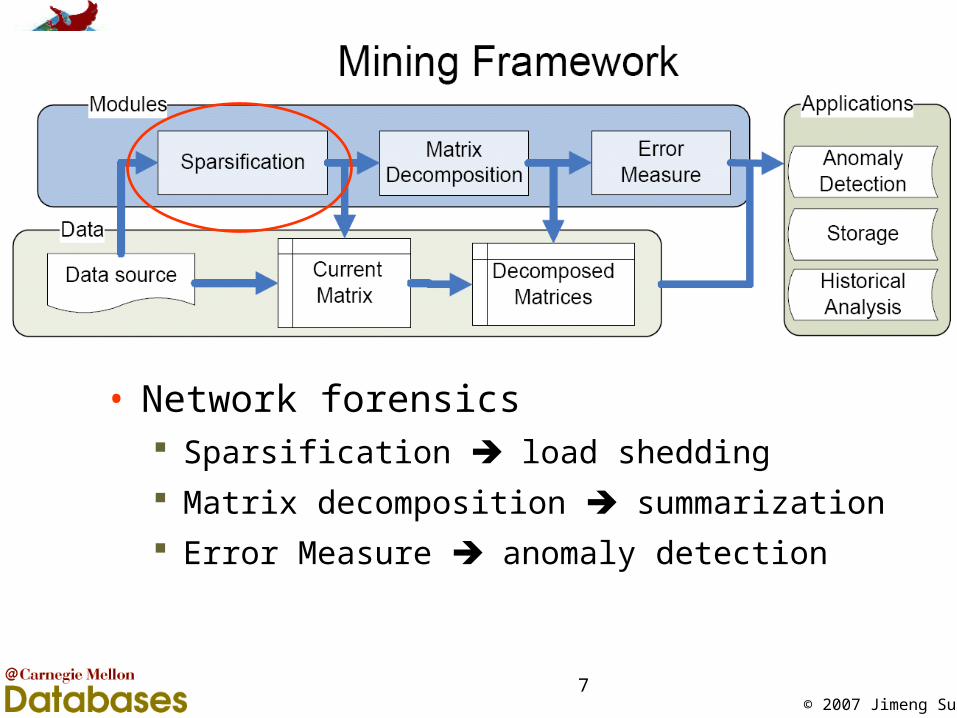
© 2007 Jimeng Sun7
• Network forensics Sparsification load shedding
Matrix decomposition summarization
Error Measure anomaly detection
© 2007 Jimeng Sun8
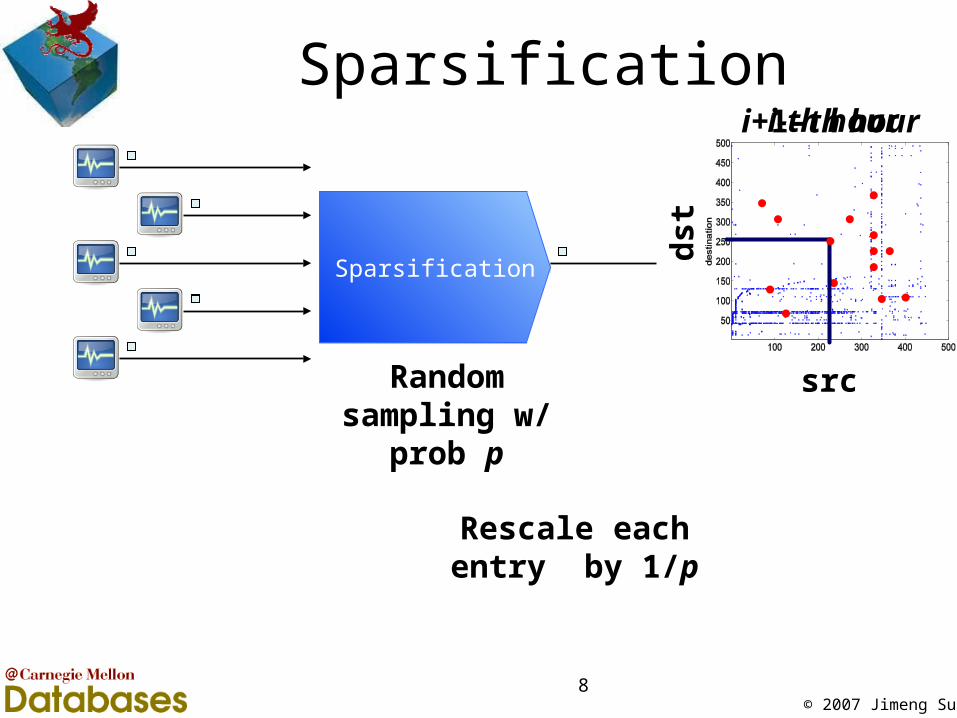
i-th hour
Sparsification
Sparsification
Random sampling w/ prob p
i+1-th hour
Rescale each entry by 1/p
src
dst
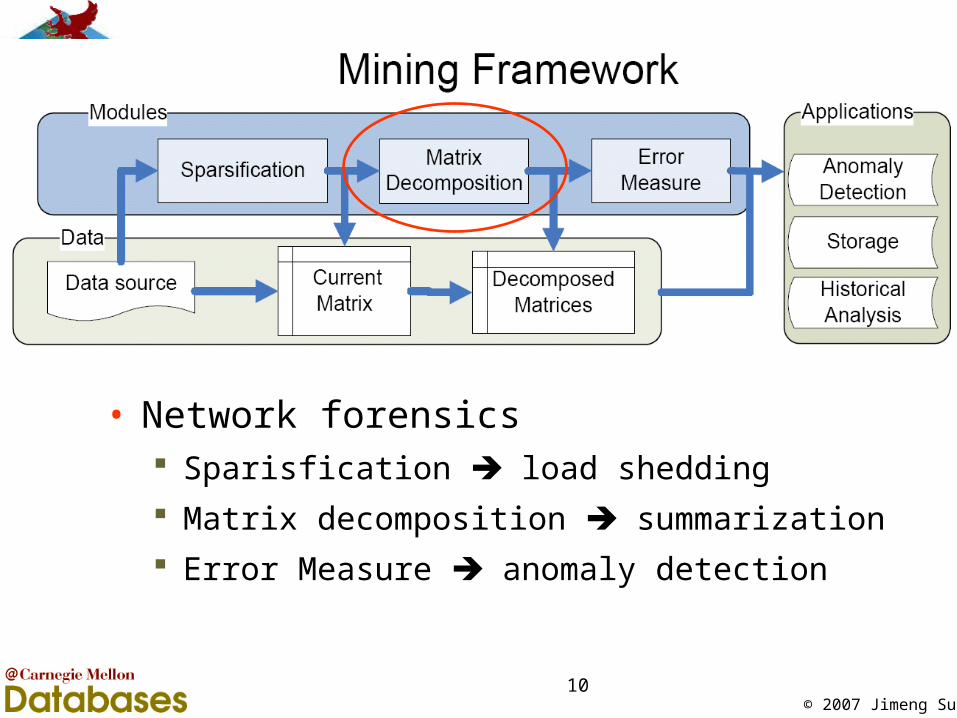
© 2007 Jimeng Sun10
• Network forensics Sparisfication load shedding
Matrix decomposition summarization
Error Measure anomaly detection

© 2007 Jimeng Sun11
Matrix decomposition
• Goal: Summarize traffic matrices
• Why? Anomaly detection
• How? Singular Value Decomposition (SVD) - existing
CUR Decomposition - existing
Compact Matrix Decomposition (CMD) - new
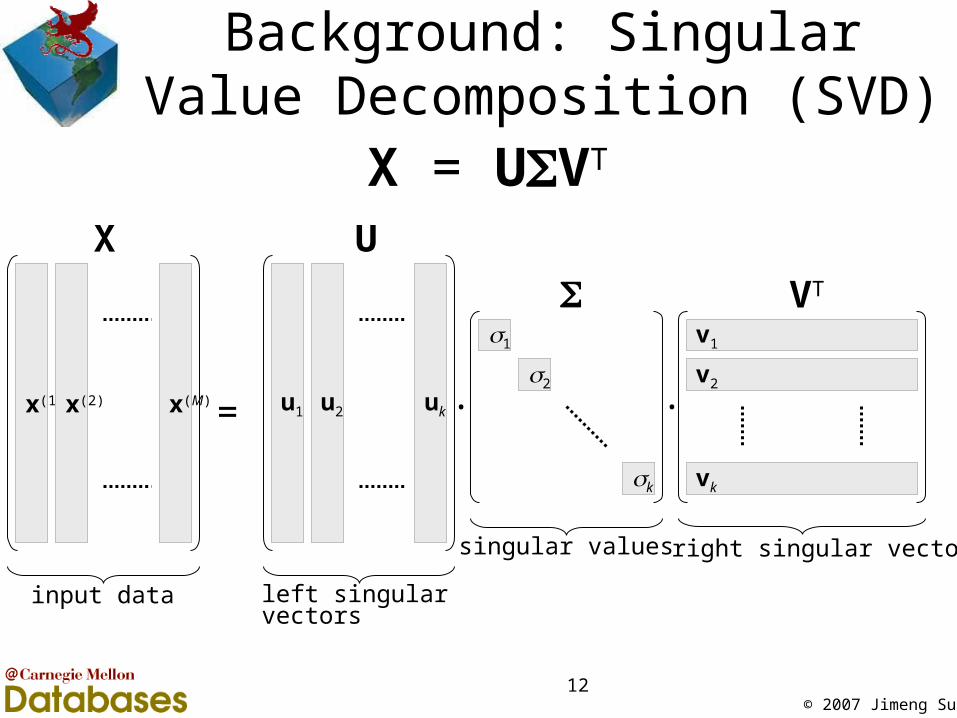
© 2007 Jimeng Sun12
Background: Singular Value Decomposition (SVD)
X = UVT
u1 u2 ukx(1) x(2) x(M) = .
v1
v2
vk
.
1
2
k
X U
VT
right singular vectors
input data left singular vectors
singular values

© 2007 Jimeng Sun13
Background: SVD applications
• Low-rank approximation
• Pseudo-inverse: M+= V-1UT
• Principle component analysis
• Latent semantic indexing
• Webpage ranking: Kleinberg’s HITS score

© 2007 Jimeng Sun14
Pros and cons of SVD
+ Optimal low-rank approximation
• in L2 and Frobenius norm
- Interpretability problem:
A singular vector specifies a linear combination of all input columns or rows.
- Lack of Sparsity
Singular vectors are usually dense
1st left singular vector
=U
VT

© 2007 Jimeng Sun15
Matrix decomposition
• Goal: Summarize traffic matrices
• Why? Anomaly detection
• How?
× Singular Value Decomposition (SVD) - existing
CUR Decomposition - existing
Compact Matrix Decomposition (CMD) - new
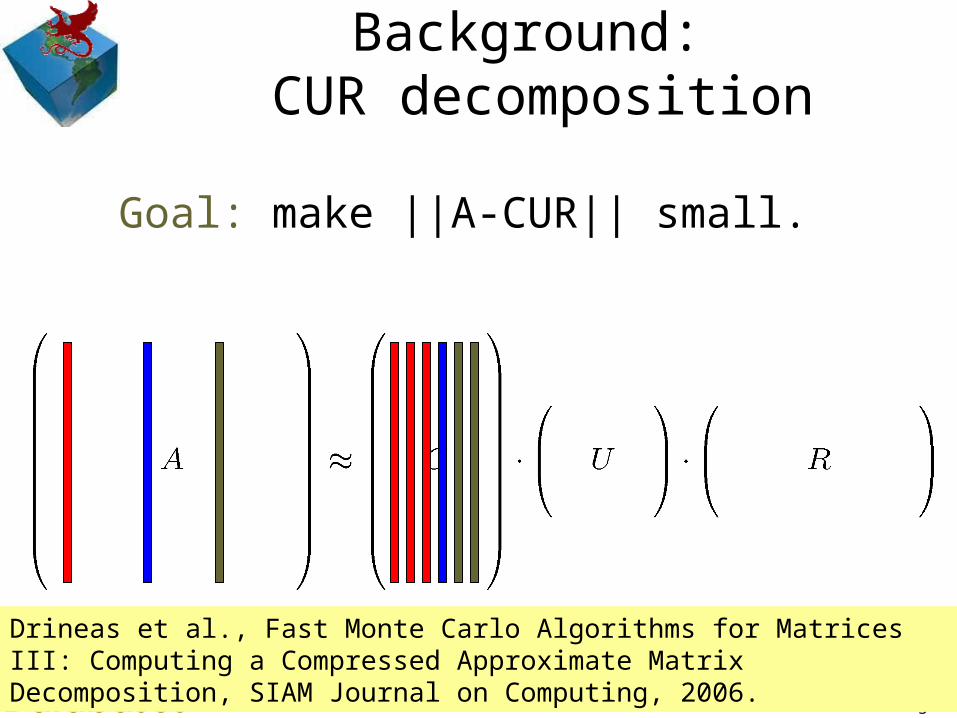
© 2007 Jimeng Sun16
Background: CUR decomposition
Goal: make ||A-CUR|| small.
Drineas et al., Fast Monte Carlo Algorithms for Matrices III: Computing a Compressed Approximate Matrix Decomposition, SIAM Journal on Computing, 2006.
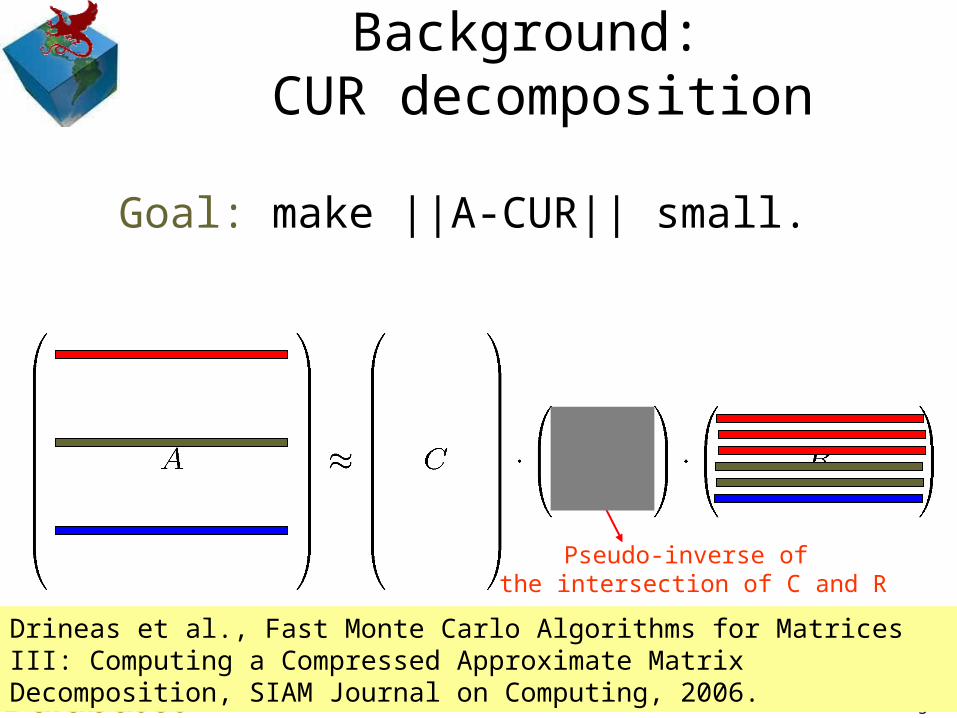
© 2007 Jimeng Sun17
Background: CUR decomposition
Drineas et al., Fast Monte Carlo Algorithms for Matrices III: Computing a Compressed Approximate Matrix Decomposition, SIAM Journal on Computing, 2006.
Goal: make ||A-CUR|| small.
Pseudo-inverse of the intersection of C and R

© 2007 Jimeng Sun18
CUR: provably good approximation to SVD
• Assume Ak is the “best” rank k approximation to A (through SVD).
Thm [Drineas et al.] CUR in O(mn) time achieves
||A-CUR|| <= ||A-Ak||+ ||A||
with probability at least 1-, by picking O( k log(1/) / 2 ) columns, and
O( k2 log3(1/) / 6 ) rowsDrineas et al., Fast Monte Carlo Algorithms for Matrices III: Computing a Compressed Approximate Matrix Decomposition, SIAM Journal on Computing, 2006.

© 2007 Jimeng Sun19
Background: CUR applications
• DNA SNP Data analysis
• Recommendation system
• Fast kernel approximation
1. Intra- and interpopulation genotype reconstruction from tagging SNPs, P. Paschou, M. W. Mahoney, A. Javed, J. R. Kidd, A. J. Pakstis, S. Gu, K. K. Kidd, and P. Drineas, Genome Research, 17(1), 96-107 (2007)
2. Tensor-CUR Decompositions For Tensor-Based Data, M. W. Mahoney, M. Maggioni, and P. Drineas, Proc. 12-th Annual SIGKDD, 327-336 (2006)

© 2007 Jimeng Sun20
Pros and cons of CUR
+ Easy interpretation• Since the basis vectors are actual
columns and rows
+ Sparse basis• Since the basis vectors are actual
columns and rows
- Duplicate columns and rows• Columns of large norms will be
sampled many times
Singular vector
Actual column

© 2007 Jimeng Sun21
Matrix decomposition
• Goal: Summarize traffic matrices
• Why? Anomaly detection
• How?
× Singular Value Decomposition (SVD) – existing
× CUR Decomposition - existing
Compact Matrix Decomposition (CMD) - new

© 2007 Jimeng Sun22
Compact Matrix Decomposition (CMD)
• Given a matrix A, find three matrices C, U, R such that ||A-CUR|| is small
No duplicates in C and R
ACd
Rd
Cs
Rs
U = X+
X
¼Finding U is more involved!
=
CUR CMD
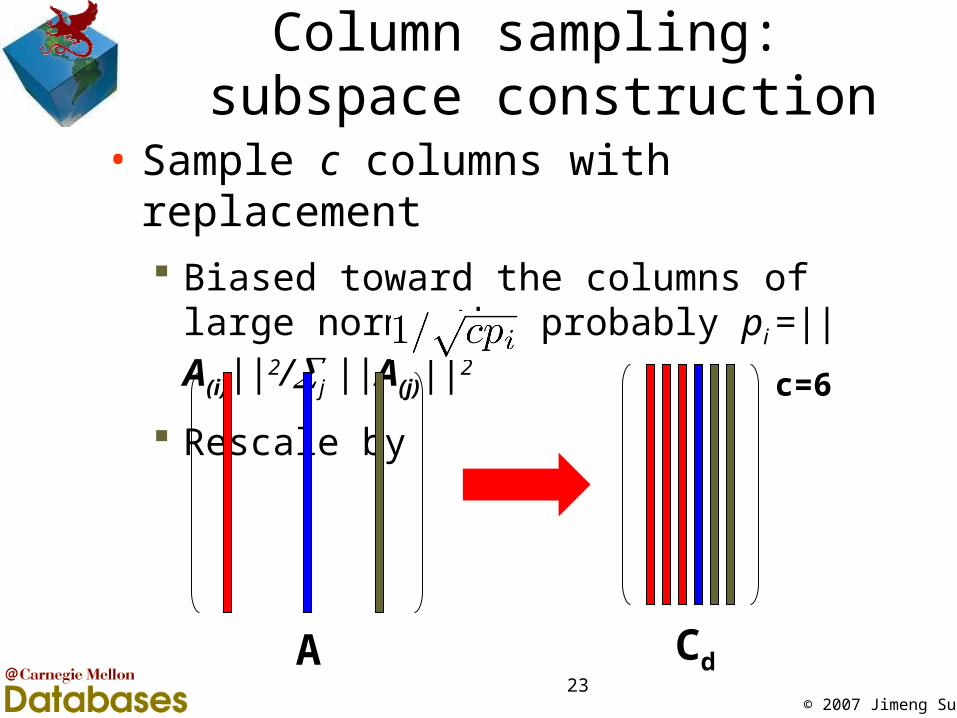
© 2007 Jimeng Sun23
Column sampling: subspace construction
• Sample c columns with replacement Biased toward the columns of large norm,
the probably pi =||A(i)||2/j ||A(j)||2
Rescale by
A Cd
c=6

© 2007 Jimeng Sun24
Column sampling: duplicate column removal
• Remove duplicate columns
• Scale the columns by the square root of the number of duplicates
p3
CsCd

© 2007 Jimeng Sun25
Column sampling:correctness proof
Thm: Matrix Cs and Cd have the same singular values and left singular vectors See our paper for the proof
Implication: Column duplicate removal preserves the sample top-k subspace

© 2007 Jimeng Sun26
• Low rank approximation
CMD construction
~A = U cU Tc A
= CV C § ¡ 1C (CV C § ¡ 1
C )T A
= CV C § ¡ 2C V T
C C T A
= CUA
~A = U cU Tc A
= CV C § ¡ 1C (CV C § ¡ 1
C )T A
= CV C § ¡ 2C V T
C C T A
= CUA
~A = CUR
Project to top-c column subspace
C+
c £ mbig, dense entire
matrix
C
m £ csparse
¼
details

© 2007 Jimeng Sun27
Row sampling
• Approximate matrix multiplication Sample and rescale the columns and rows
• Remove duplicate rows and scale the rows by the number of duplicates C C+ A ¼ C U R
C+c£m
An£m
Uc£r
Rr£m
details
© 2007 Jimeng Sun28
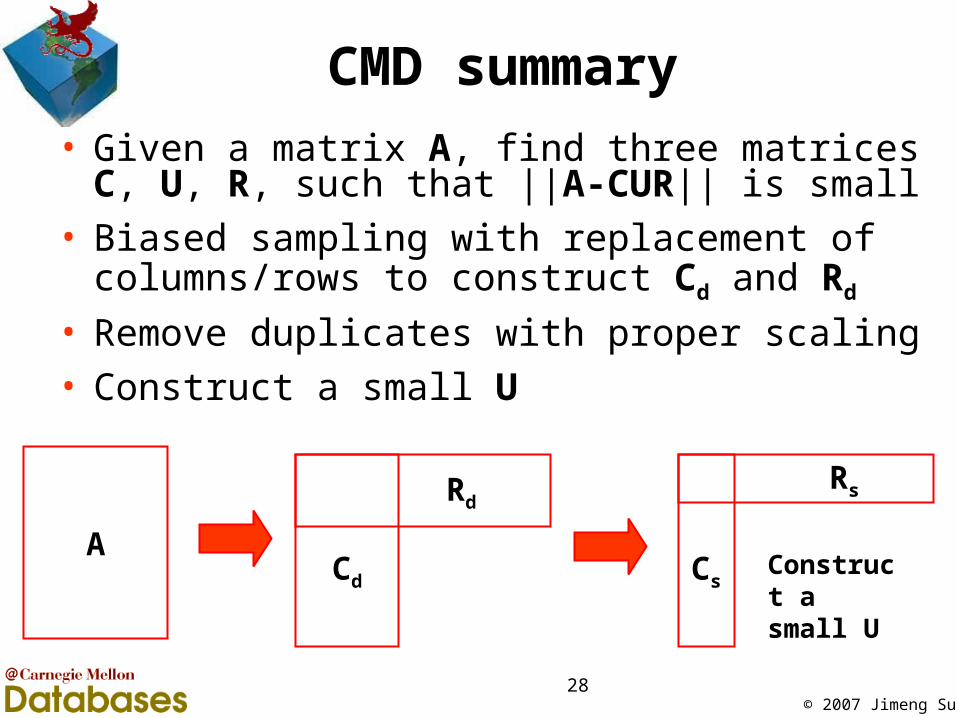
CMD summary• Given a matrix A, find three matrices C, U, R, such
that ||A-CUR|| is small
• Biased sampling with replacement of columns/rows to construct Cd and Rd
• Remove duplicates with proper scaling
• Construct a small U
ACd
Rd
Cs
Rs
Construct a small U
© 2007 Jimeng Sun29
• Network forensics Sparsification load shedding
Matrix decomposition summarization
Error Measure anomaly detection

© 2007 Jimeng Sun30
Error Measure
• True error
• Approximated error
for some sample elements in a set S

© 2007 Jimeng Sun31
Outline• Motivation
• Problem definition
• Proposed mining framework Sparsification
Matrix decomposition
Error Measure
• Experiments
• Related work
• Conclusion

© 2007 Jimeng Sun32
Experiment datasets • Network flow data
22k x 22k matrices
Every matrix corresponds to 1 hour of data
Elements are the log(packet count +1)
1200 hours, 500 GB raw trace
• DBLP bibliographic data Author-conference graphs from 1980 to 2004
428K authors, 3659 conferences
Elements are the numbers of papers published by the authors

© 2007 Jimeng Sun33
Experiment design
1. CMD vs. SVD, CUR w.r.t. Space
CPU time
Accuracy = 1 – relative sum square error
2. Evaluation of other modules Sparsification, Error measure
3. Case-study on network anomaly detection
© 2007 Jimeng Sun34
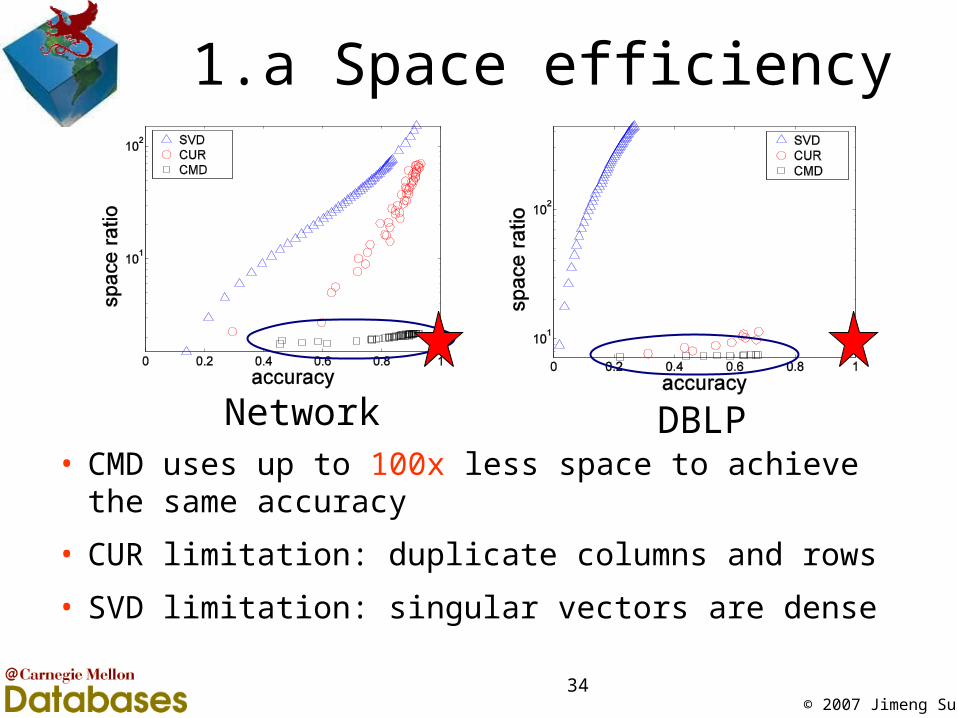
1.a Space efficiency
• CMD uses up to 100x less space to achieve the same accuracy
• CUR limitation: duplicate columns and rows
• SVD limitation: singular vectors are dense
Network DBLP
© 2007 Jimeng Sun35
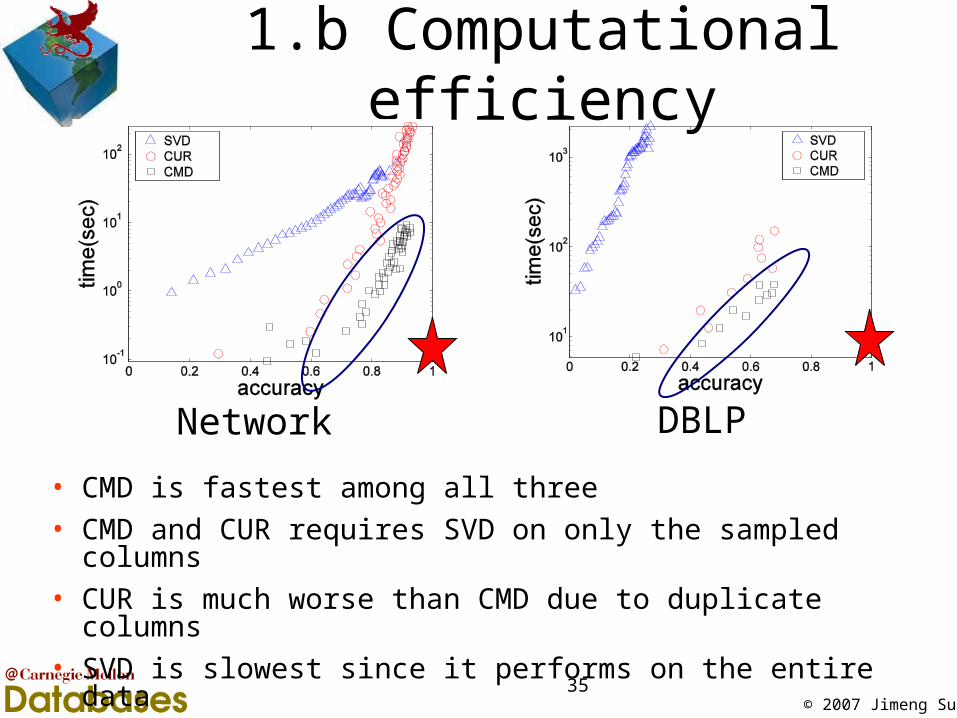
1.b Computational efficiency
• CMD is fastest among all three
• CMD and CUR requires SVD on only the sampled columns
• CUR is much worse than CMD due to duplicate columns
• SVD is slowest since it performs on the entire data
Network DBLP
© 2007 Jimeng Sun36
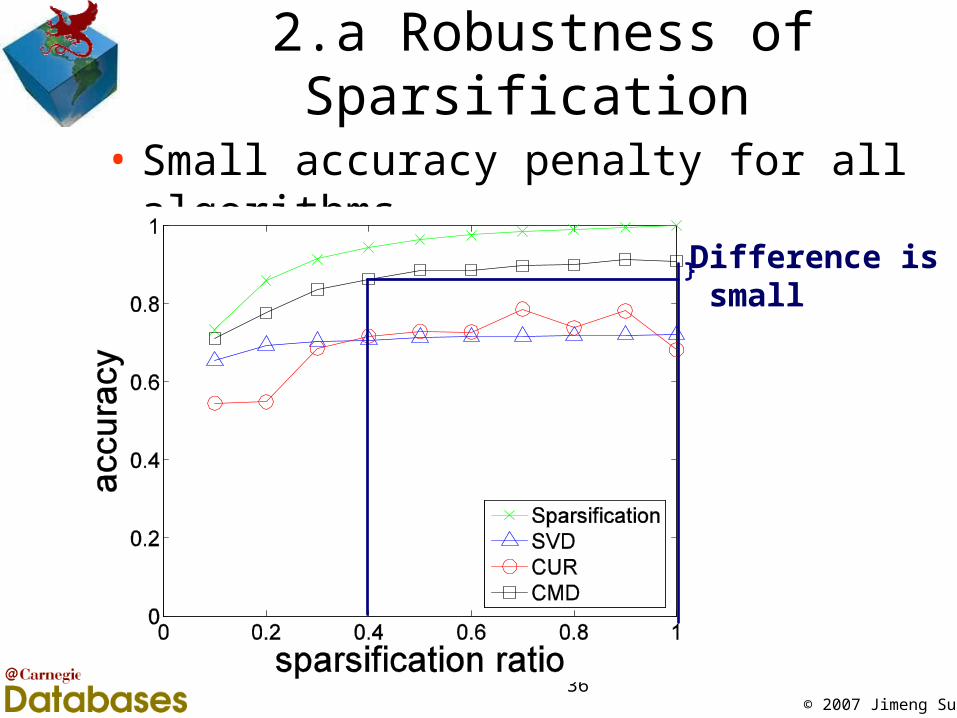
2.a Robustness of Sparsification
• Small accuracy penalty for all algorithms
Difference is small
© 2007 Jimeng Sun37
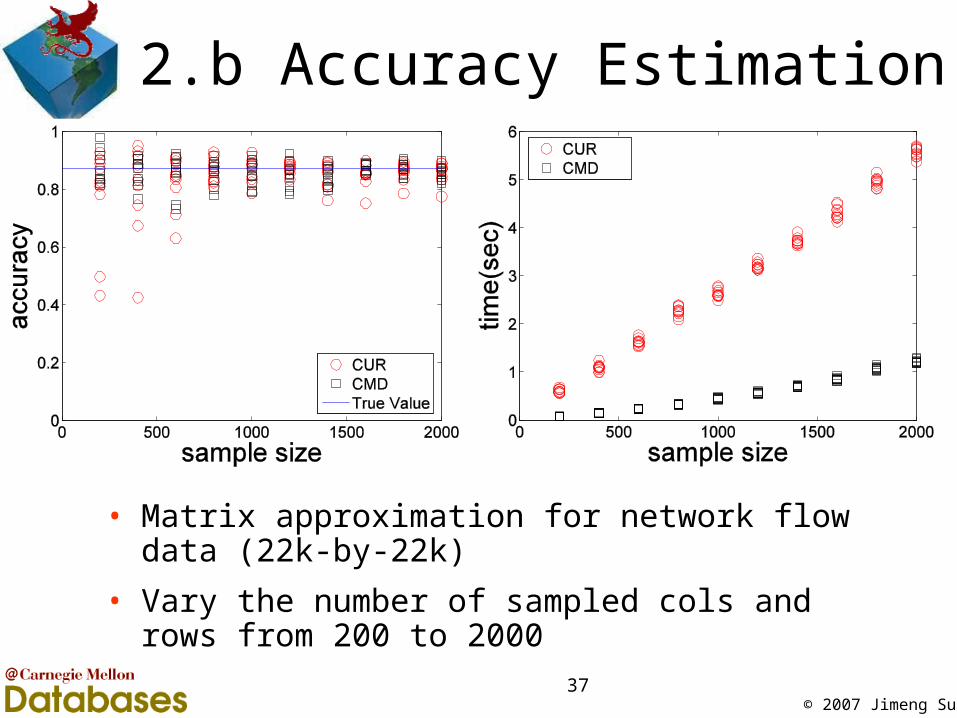
2.b Accuracy Estimation
• Matrix approximation for network flow data (22k-by-22k)
• Vary the number of sampled cols and rows from 200 to 2000
© 2007 Jimeng Sun38
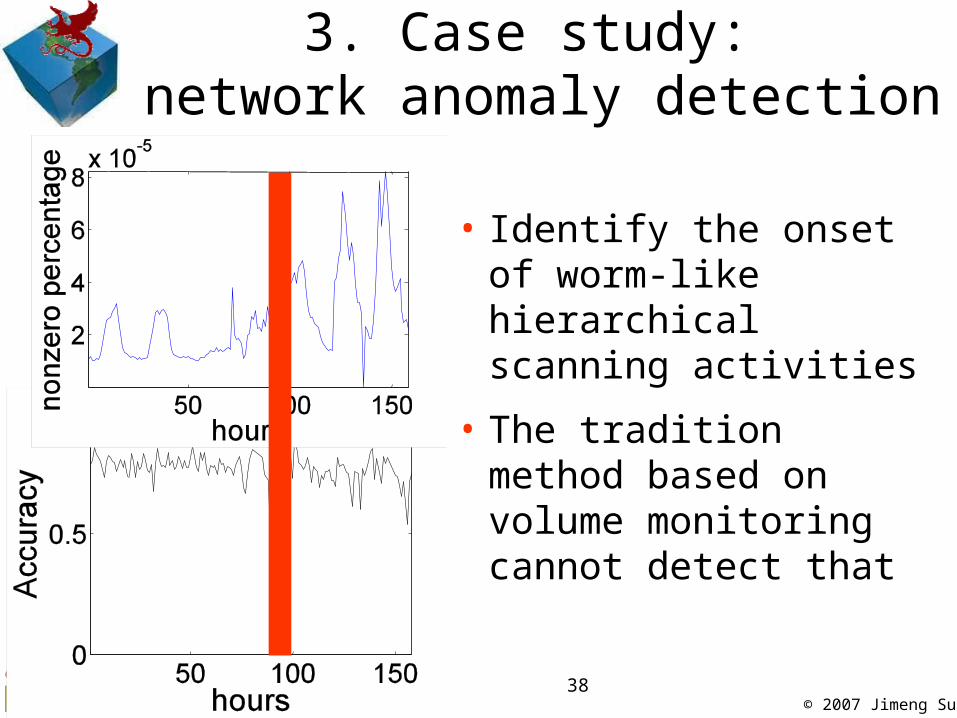
3. Case study: network anomaly detection
• Identify the onset of worm-like hierarchical scanning activities
• The tradition method based on volume monitoring cannot detect that

© 2007 Jimeng Sun39
Outline• Motivation
• Problem definition
• Proposed mining framework Sparsification
Matrix decomposition
Error Measure
• Experiments
• Related work
• Conclusion

© 2007 Jimeng Sun40
CUR decompositionsStewart, Berry, Pulatova
(Num. Math.’99, TOMS’05 )
C: variant of the QR algorithm,
U: minimizes ||A-CUR||F
R: variant of the QR algorithm,
No a priori bounds
Solid experimental performance
Goreinov, Tyrtyshnikov, & Zamarashkin
(LAA ’97, Cont. Math. ’01)
C: columns that span max volume
U: W+
R: rows that span max volume
Existential result
Error bounds depend on ||W+||2
Spectral norm bounds!
Williams & Seeger
(NIPS ’00)
C: uniformly at random
U: W+
R: uniformly at random
Experimental evaluation
A is assumed PSD
Connections to Nystrom method
Drineas, Kannan, & Mahoney (SODA ’03, ’04)
C: w.r.t. column lengths
U: in linear/constant time
R: w.r.t. row lengths
Randomized algorithm
Provable, a priori, bounds
Explicit dependency on A –Ak
Drineas, Mahoney, & Muthukrishnan
(’05, ’06)
C: depends on singular vectors of A.
U: (almost) W+
R: depends on singular vectors of C
(1+) approximation to A –Ak
Computable in SVDk(A) time.
Acknowledge to Petros Drineas for this slide
Monte-Carlo Sampling approach
Deterministic approach
CMD can help here!

© 2007 Jimeng Sun41
Other related work
• Low-rank approximation Frieze, Kannan, Vempala (1998)
Achlioptas and McSherry (2001)
Sarlós (2006)
Zhang, Zha, Simon (2002)
• Other sparse approximations Sebro, Jaakkola (2004): max-margin matrix
factorization
Nonnegative matrix factorization
L1 regularization

© 2007 Jimeng Sun42
ConclusionHow to summarize sparse matrices
in a concise and intuitive manner?
1.Provable accuracy guarantee2.10x to 100x improvement3.Interpretability4.Applied to 500 Gb network
forensics data
Proposed method - CMD

© 2007 Jimeng Sun43
Thank you
• Contact: Jimeng Sun
• Acknowledgement to Petros Drineas and Michael Mahoney for the insightful discussion/help on CUR decomposition

© 2007 Jimeng Sun44
The sparsity property
SVD: A = U VT
Big but sparse Big and dense
CMD: A = C U R
Big but sparse Big but sparse
dense but small
sparse and small

© 2007 Jimeng Sun45
Column sampling: subspace construction
• Biased sampling with replacement of the “large” columns

© 2007 Jimeng Sun46
Column sampling: duplicate column removal
• Remove duplicate columns and scale the column by the square root of the number of duplicates

© 2007 Jimeng Sun47
Summary on CMD• CMD: A C U R
C/R: sampled and scaled columns and rows without duplicates (sparse)
U: a small matrix (dense)
• Properties Interpretability: interpret matrix by sampled rows
and columns
Efficiency: in computation and space
• Application Network forensics: Anomaly detection

© 2007 Jimeng Sun48
ConclusionHow to summarize sparse matrices
in a concise and intuitive manner?
Network Forensics1. Sparsification through
sampling 2. Low-rank approximation3. Error measure
Application
CMD: low rank approximation 1. sampled and scaled columns
and rows without duplicates (sparse)
2. a small matrix (dense)
Theory
1. Provable accuracy guarantee
2. 10x to 100x improvement3. Interpretability4. Applied to 500 Gb network
forensics data
CMD:


















