
Лекция №1 "Задачи Data Mining"
24
Лекция 1 Задачи Data Mining Николай Анохин 25 сентября 2014 г.
-
Upload
technosphere1 -
Category
Education
-
view
268 -
download
1
Transcript of Лекция №1 "Задачи Data Mining"

Лекция 1Задачи Data Mining
Николай Анохин
25 сентября 2014 г.

План лекции
Структура курса
Что такое Data Mining
Процесс Data Mining
Exploratory data analysis
2 / 23

Структура курсаМодуль 1
1. Задачи Data Mining (Николай Анохин)
2. Задача кластеризации и EM-алгоритм (Николай Анохин)
3. Различные алгоритмы кластеризации (Николай Анохин)H
4. Задача классификации (Николай Анохин)
5. Naive Bayes (Николай Анохин)
6. Линейные модели (Николай Анохин)
7. Метод опорных векторов (Николай Анохин)HP
Модуль 2
1. Снижение размерности пространства (Владимир Гулин)
2. Алгоритмические композиции 1 (Владимир Гулин)
3. Алгоритмические композиции 2 (Владимир Гулин)H
4. Нейросети, обучение с учителем (Павел Нестеров)H
5. Нейросети, обучение без учителя (Павел Нестеров)
6. Нейросети, глубокие сети (Павел Нестеров)
3 / 23
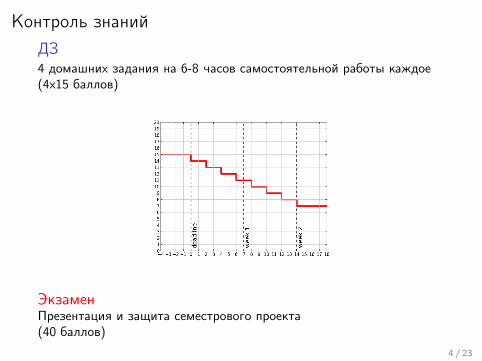
Контроль знанийДЗ4 домашних задания на 6-8 часов самостоятельной работы каждое(4x15 баллов)
ЭкзаменПрезентация и защита семестрового проекта(40 баллов)
4 / 23

Правила
+ Можно задавать вопросы по ходу лекции+ Можно входить и выходить, не мешая коллегам— Нельзя нарушать порядок в аудитории— Нельзя разговаривать по телефонуI Общение с преподавателем на “Вы”
Ваши правила?
5 / 23

DM как KDD
Data MiningПроцесс извлечения знаний из различных источников данных, такихкак базы данных, текст, картинки, видео и т.д. Полученные знаниядолжны быть достоверными, полезными и интерпретируемыми.
6 / 23

DM как моделирование
Data MiningПроцесс построения модели, хорошо описывающей закономерности,которые порождают данные.
Подходы к построению моделей4 cтатистический4 на основании машинного обучения6 вычислительный
7 / 23

DM и DS
Data ScientistPerson who is better at statistics than any software engineer and betterat software engineering than any statistician(J. Wills, Data Scientist at Cloudera Inc.)
Data-6 -architecture6 -acquisition4 -analysis6 -archiving
8 / 23
Success stories
(a) Google (b) LinkedIn
(c) KnowDelay (d) Handwritten digits
9 / 23

Fail (Программа TIA)I Наблюдаем 109 человекI Человек в среднем посещает отель раз в 100 днейI Есть 105 отелей на 100 человек каждыйI Проверим посещения за 1000 дней
Вероятность для конкретной пары встретиться в отеле в конкретныйдень:
p1 =
(1
100
)2
· 10−5 = 10−9
Всего пар людей
npp = C 109
2 ≈ (109)2
2= 5 · 1017
а пар дней
npd = C 103
2 ≈ (103)2
2= 5 · 105
Ожидаемое количество “подозрительных” встреч в отелях
N = p21nppnpd = 250000 >> 10
10 / 23

Принцип Бонферрони
Вычислить количество рассматриваемых событий припредположении их полной случайности. Если это количествонамного превосходит количество событий, о котором идет речь взадаче, полученные результаты нельзя будет считать достоверными.
11 / 23
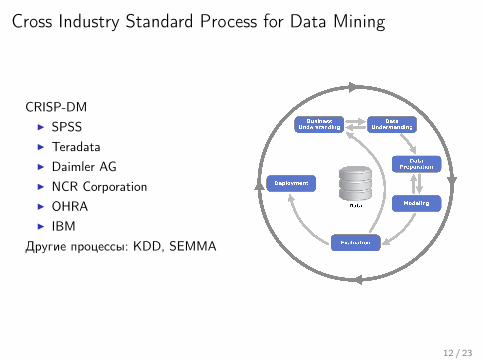
Cross Industry Standard Process for Data Mining
CRISP-DMI SPSSI TeradataI Daimler AGI NCR CorporationI OHRAI IBM
Другие процессы: KDD, SEMMA
12 / 23
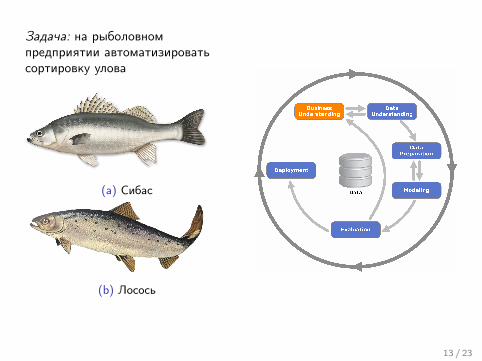
Задача: на рыболовномпредприятии автоматизироватьсортировку улова
(a) Сибас
(b) Лосось
13 / 23
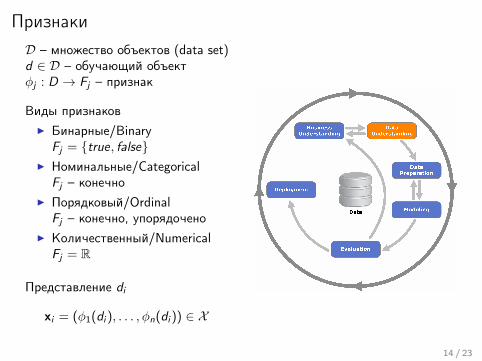
ПризнакиD – множество объектов (data set)d ∈ D – обучающий объектφj : D → Fj – признак
Виды признаковI Бинарные/Binary
Fj = {true, false}I Номинальные/Categorical
Fj – конечноI Порядковый/Ordinal
Fj – конечно, упорядоченоI Количественный/Numerical
Fj = R
Представление di
xi = (φ1(di ), . . . , φn(di )) ∈ X
14 / 23

I Удаление шумаI Заполнение отсутствующих
значенийI Трансформация факторовI Выбор факторовI Использование априорных
знаний
В итоге:
X =
x1. . .xN
, xi ∈ X
Y =
y1. . .yN
, yi ∈ Y
15 / 23

Модельсемейство параметрическихфункций вида
H = {h(x, θ) : X ×Θ→ Y}
Алгоритм обучениявыбор наилучших параметров θ∗
A(X ,Y ) : (X × Y)N → Θ
В итоге:
h∗(x) = h(x, θ∗)
16 / 23
I точность или аппроксимация?I bias или variance?I интерпретируемость или
качество?
17 / 23
18 / 23

Exploratory data analysis
EDA направлен на предварительное изучение данныхI формироваие гипотез относително структуры данныхI выбор необходимых инструментов анализа
Особенность метода состоит в визуализации и поиске важныххарактеристик и тенденций
19 / 23
Примеры
(a) Plot (b) Scatter (c) Barplot
(d) Piechart (e) Heatmap (f) Boxplot
20 / 23

Полезные советы
I Все познается в сравненииI Причинно-следственные связиI Размерность имеет значение
(больше-лучше)
I Не избегать поясненийI Content is king
21 / 23

ЗадачаДано: информация о посещении пользователями интернет-сайтовТребуется: исследовать распределение количества уникальныхпользователей в зависимости от популярности сайта
Пошаговая инструкция1. Скачать файл с данными (400M) http://bit.ly/1xdOrHD2. Скачать и запустить шаблон кода на python
http://bit.ly/1B6fEcO
$ python eda.py -h$ python eda.py -n 20 eda.dat
3. Заполнить функцию top_domain_user_counts4. Заполнить функцию plot_log_top_domains и посмотреть на
распределение в log-log шкале5. Заполнить функцию plot_linear_model, попутно осознав
параметры модели6. Выписать полученное распределение nusers(rank)
22 / 23

Вопросы


















